背景:部署Sklearn时发现…什么反应也没有,查看controller日志发现,predictor没能正确部署,于是干脆梳理一遍吧
从部署开始
按照官方文档,我们可用通过yaml文件部署一个 sklearn 的 inferenceService ,不过我们从源码也可以发现如下的 python 测试代码,也可以实现使用k8s client来创建一个 V1beta1InferenceService :
@pytest.mark.predictor
@pytest.mark.asyncio(scope="session")
async def test_sklearn_kserve(rest_v1_client):
service_name = "isvc-sklearn"
predictor = V1beta1PredictorSpec(
min_replicas=1,
sklearn=V1beta1SKLearnSpec(
storage_uri="gs://kfserving-examples/models/sklearn/1.0/model",
resources=V1ResourceRequirements(
requests={"cpu": "50m", "memory": "128Mi"},
limits={"cpu": "100m", "memory": "256Mi"},
),
),
)
isvc = V1beta1InferenceService(
api_version=constants.KSERVE_V1BETA1,
kind=constants.KSERVE_KIND_INFERENCESERVICE,
metadata=client.V1ObjectMeta(
name=service_name, namespace=KSERVE_TEST_NAMESPACE
),
spec=V1beta1InferenceServiceSpec(predictor=predictor),
)
kserve_client = KServeClient(
config_file=os.environ.get("KUBECONFIG", "~/.kube/config")
)
kserve_client.create(isvc)
kserve_client.wait_isvc_ready(service_name, namespace=KSERVE_TEST_NAMESPACE)
res = await predict_isvc(rest_v1_client, service_name, "./data/iris_input.json")
assert res["predictions"] == [1, 1]
kserve_client.delete(service_name, KSERVE_TEST_NAMESPACE)当我们在集群中创建一个 V1beta1InferenceService 时,会发生什么呢?
控制器
当我们研读kserve源码的时候,会发现Kserve是使用kubebuilder开发的,实际上也就是k8s的operator开发。相关内容可以看看Kubebuilder(1)-Get started。
在 cmd/manager/main.go 文件中,我们可以看到控制器的相关代码。而与 InferenceService 有关的主要是下面这两段:
setupLog.Info("Setting up v1beta1 controller")
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartRecordingToSink(&typedcorev1.EventSinkImpl{Interface: clientSet.CoreV1().Events("")})
if err = (&v1beta1controller.InferenceServiceReconciler{
Client: mgr.GetClient(),
Clientset: clientSet,
Log: ctrl.Log.WithName("v1beta1Controllers").WithName("InferenceService"),
Scheme: mgr.GetScheme(),
Recorder: eventBroadcaster.NewRecorder(
mgr.GetScheme(), corev1.EventSource{Component: "v1beta1Controllers"}),
}).SetupWithManager(mgr, deployConfig, ingressConfig); err != nil {
setupLog.Error(err, "unable to create controller", "v1beta1Controller", "InferenceService")
os.Exit(1)
}以及
if err = ctrl.NewWebhookManagedBy(mgr).
For(&v1beta1.InferenceService{}).
WithDefaulter(&v1beta1.InferenceServiceDefaulter{}).
WithValidator(&v1beta1.InferenceServiceValidator{}).
Complete(); err != nil {
setupLog.Error(err, "unable to create webhook", "webhook", "v1beta1")
os.Exit(1)
}
if err = ctrl.NewWebhookManagedBy(mgr).
For(&v1alpha1.LocalModelCache{}).
WithValidator(&localmodelcache.LocalModelCacheValidator{Client: mgr.GetClient()}).
Complete(); err != nil {
setupLog.Error(err, "unable to create webhook", "webhook", "localmodelcache")
os.Exit(1)
}分别配置控制器和webhook准入。
SetupWithManager 方法实现了控制器的自适应注册机制,根据集群环境动态配置监听资源。
// 1. 基础监听配置
ctrlBuilder := ctrl.NewControllerManagedBy(mgr).
For(&v1beta1.InferenceService{}). // 主资源
Owns(&appsv1.Deployment{}) // 必需组件// 2. Knative 服务监听
if ksvcFound {
ctrlBuilder = ctrlBuilder.Owns(&knservingv1.Service{})
}// 3. 入口配置
// Istio VirtualService
if vsFound && !ingressConfig.DisableIstioVirtualHost {
ctrlBuilder = ctrlBuilder.Owns(&istioclientv1beta1.VirtualService{})
}
// Gateway API vs Ingress
if ingressConfig.EnableGatewayAPI {
ctrlBuilder = ctrlBuilder.Owns(&gatewayapiv1.HTTPRoute{})
} else {
ctrlBuilder = ctrlBuilder.Owns(&netv1.Ingress{})
}- 使用
Owns()建立资源所有权关系 - 通过配置控制 Istio 和网关 API 的使用
- 错误处理和日志记录完善
然后让我们回到控制器的最主要方法—— Reconcile 。
Reconcile
Kserve 的调和过程其实是较为复杂的,涉及到了很多组件与K8s资源的调和。不过,主要的入口还是在 pkg/controller/v1beta1/inferenceservice/controller.go 中。
在 (r *InferenceServiceReconciler) Reconcile 中,首先做的就是把 isvc 实例和 ConfigMap 拿到,这也符合在之前的博客中写到的流程。
相对应的isvc 实例内容可能如下:
kubectl describe isvc sklearn-iris -n kserve-test
Name: sklearn-iris
Namespace: kserve-test
Labels: <none>
Annotations: <none>
API Version: serving.kserve.io/v1beta1
Kind: InferenceService
Metadata:
Creation Timestamp: 2025-03-15T12:41:59Z
Finalizers:
inferenceservice.finalizers
Generation: 1
Resource Version: 1178878
UID: d8cca840-38d7-415c-87fd-12e120797f14
Spec:
Predictor:
Model:
Model Format:
Name: sklearn
Name:
Resources:
Storage Uri: gs://kfserving-examples/models/sklearn/1.0/model
Status:
Address:
URL: http://sklearn-iris.kserve-test.svc.cluster.local
Components:
Predictor:
Address:
URL: http://sklearn-iris-predictor.kserve-test.svc.cluster.local
Latest Created Revision: sklearn-iris-predictor-00001
Latest Ready Revision: sklearn-iris-predictor-00001
Latest Rolledout Revision: sklearn-iris-predictor-00001
Traffic:
Latest Revision: true
Percent: 100
Revision Name: sklearn-iris-predictor-00001
URL: http://sklearn-iris-predictor.kserve-test.knative.example.com
Conditions:
Last Transition Time: 2025-03-15T12:42:55Z
Status: True
Type: IngressReady
Last Transition Time: 2025-03-15T12:42:54Z
Severity: Info
Status: True
Type: LatestDeploymentReady
Last Transition Time: 2025-03-15T12:42:54Z
Severity: Info
Status: True
Type: PredictorConfigurationReady
Last Transition Time: 2025-03-15T12:42:55Z
Status: True
Type: PredictorReady
Last Transition Time: 2025-03-15T12:42:55Z
Severity: Info
Status: True
Type: PredictorRouteReady
Last Transition Time: 2025-03-15T12:42:55Z
Status: True
Type: Ready
Last Transition Time: 2025-03-15T12:42:55Z
Severity: Info
Status: True
Type: RoutesReady
Model Status:
Copies:
Failed Copies: 0
Total Copies: 1
States:
Active Model State: Loaded
Target Model State: Loading
Transition Status: InProgress
Observed Generation: 1
URL: http://sklearn-iris.kserve-test.knative.example.com
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...在这段分析中,我们使用的部署模式为 Serverless 。

在获取配置后,还有一段 Finalizer 的处理过程,用于处理资源的删除。
Finalizer
在Kubernetes的Operator开发里,Finalizer是一种机制,它能够保证在删除自定义资源(CR)之前执行特定的清理操作。当你删除一个带有Finalizer的资源时,Kubernetes不会立刻将其从系统中移除,而是把资源标记为“正在删除”状态,之后会调用Finalizer中定义的清理逻辑,待清理工作完成,才会真正删除该资源。
- 工作原理
- 添加Finalizer:当你创建或者更新一个自定义资源时,Operator可以给资源添加Finalizer。Finalizer以字符串的形式存在,通常采用反向域名的格式,像
mycompany.com/my-finalizer这样。 - 删除资源:当用户请求删除带有Finalizer的资源时,Kubernetes会在资源的
metadata.deletionTimestamp字段记录删除时间,同时把资源标记为“正在删除”状态。但此时资源不会马上被删除,只有Finalizer列表为空时才会被删除。 - 执行清理操作:Operator会持续监控资源的状态,一旦发现资源处于“正在删除”状态,就会执行Finalizer里定义的清理逻辑。这些清理操作可能包括释放外部资源(如云存储、数据库连接等)、删除相关的依赖资源等。
- 移除Finalizer:当清理操作完成后,Operator会从资源的Finalizer列表里移除相应的Finalizer。当Finalizer列表为空时,Kubernetes会彻底删除该资源。
- 添加Finalizer:当你创建或者更新一个自定义资源时,Operator可以给资源添加Finalizer。Finalizer以字符串的形式存在,通常采用反向域名的格式,像
以下是一个简单的Python示例:
from kubernetes import client, config
from kubernetes.client.rest import ApiException
# 加载Kubernetes配置
config.load_kube_config()
# 创建API客户端
v1 = client.CoreV1Api()
# 定义Finalizer名称
FINALIZER_NAME = "mycompany.com/my-finalizer"
def add_finalizer(namespace, name):
try:
# 获取资源
pod = v1.read_namespaced_pod(name, namespace)
# 如果Finalizer不存在,则添加
if FINALIZER_NAME not in pod.metadata.finalizers:
pod.metadata.finalizers = pod.metadata.finalizers or []
pod.metadata.finalizers.append(FINALIZER_NAME)
v1.patch_namespaced_pod(name, namespace, pod)
print(f"Finalizer {FINALIZER_NAME} added to pod {name}")
except ApiException as e:
print(f"Exception when calling CoreV1Api->read_namespaced_pod: {e}")
def handle_deletion(namespace, name):
try:
# 获取资源
pod = v1.read_namespaced_pod(name, namespace)
# 检查是否正在删除
if pod.metadata.deletion_timestamp is not None:
if FINALIZER_NAME in pod.metadata.finalizers:
# 执行清理操作
print(f"Performing cleanup for pod {name}")
# 移除Finalizer
pod.metadata.finalizers.remove(FINALIZER_NAME)
v1.patch_namespaced_pod(name, namespace, pod)
print(f"Finalizer {FINALIZER_NAME} removed from pod {name}")
except ApiException as e:
print(f"Exception when calling CoreV1Api->read_namespaced_pod: {e}")
# 添加Finalizer示例
add_finalizer("default", "my-pod")
# 模拟删除操作
handle_deletion("default", "my-pod")而源代码则如下,主要是用于删除外部资源:
// examine DeletionTimestamp to determine if object is under deletion
if isvc.ObjectMeta.DeletionTimestamp.IsZero() {
// The object is not being deleted, so if it does not have our finalizer,
// then lets add the finalizer and update the object. This is equivalent
// registering our finalizer.
if !controllerutil.ContainsFinalizer(isvc, finalizerName) {
controllerutil.AddFinalizer(isvc, finalizerName)
patchYaml := "metadata:\n finalizers: [" + strings.Join(isvc.ObjectMeta.Finalizers, ",") + "]"
patchJson, _ := yaml.YAMLToJSON([]byte(patchYaml))
if err := r.Patch(ctx, isvc, client.RawPatch(types.MergePatchType, patchJson)); err != nil {
return ctrl.Result{}, err
}
}
} else {
// The object is being deleted
if controllerutil.ContainsFinalizer(isvc, finalizerName) {
// our finalizer is present, so lets handle any external dependency
if err := r.deleteExternalResources(ctx, isvc); err != nil {
// if fail to delete the external dependency here, return with error
// so that it can be retried
return ctrl.Result{}, err
}
// remove our finalizer from the list and update it.
controllerutil.RemoveFinalizer(isvc, finalizerName)
patchYaml := "metadata:\n finalizers: [" + strings.Join(isvc.ObjectMeta.Finalizers, ",") + "]"
patchJson, _ := yaml.YAMLToJSON([]byte(patchYaml))
if err := r.Patch(ctx, isvc, client.RawPatch(types.MergePatchType, patchJson)); err != nil {
return ctrl.Result{}, err
}
}
// Stop reconciliation as the item is being deleted
return ctrl.Result{}, nil
}CaBundle 调和
Kserve 在某次 Issue 中,为各个推理服务添加了一个 storageInitializer 。它会被注入到节点Pod上,为各个服务提供统一的模型参数下载服务。
在 CaBundled 的调和过程中,ReconcileCaBundleConfigMap 方法会比较期望的 CA 证书包配置映射(desiredConfigMap)和当前 Kubernetes 集群中实际存在的配置映射,依据对比结果进行创建、更新或不做操作。
配置一般如下:
{
"storageSpecSecretName": "storage-config",
"storageSecretNameAnnotation": "serving.kserve.io/storageSecretName",
"gcs": {
"gcsCredentialFileName": "gcloud-application-credentials.json"
},
"s3": {
"s3AccessKeyIDName": "AWS_ACCESS_KEY_ID",
"s3SecretAccessKeyName": "AWS_SECRET_ACCESS_KEY",
"s3Endpoint": "",
"s3UseHttps": "",
"s3Region": "",
"s3VerifySSL": "",
"s3UseVirtualBucket": "",
"s3UseAccelerate": "",
"s3UseAnonymousCredential": "",
"s3CABundle": ""
}
}主要组件调和
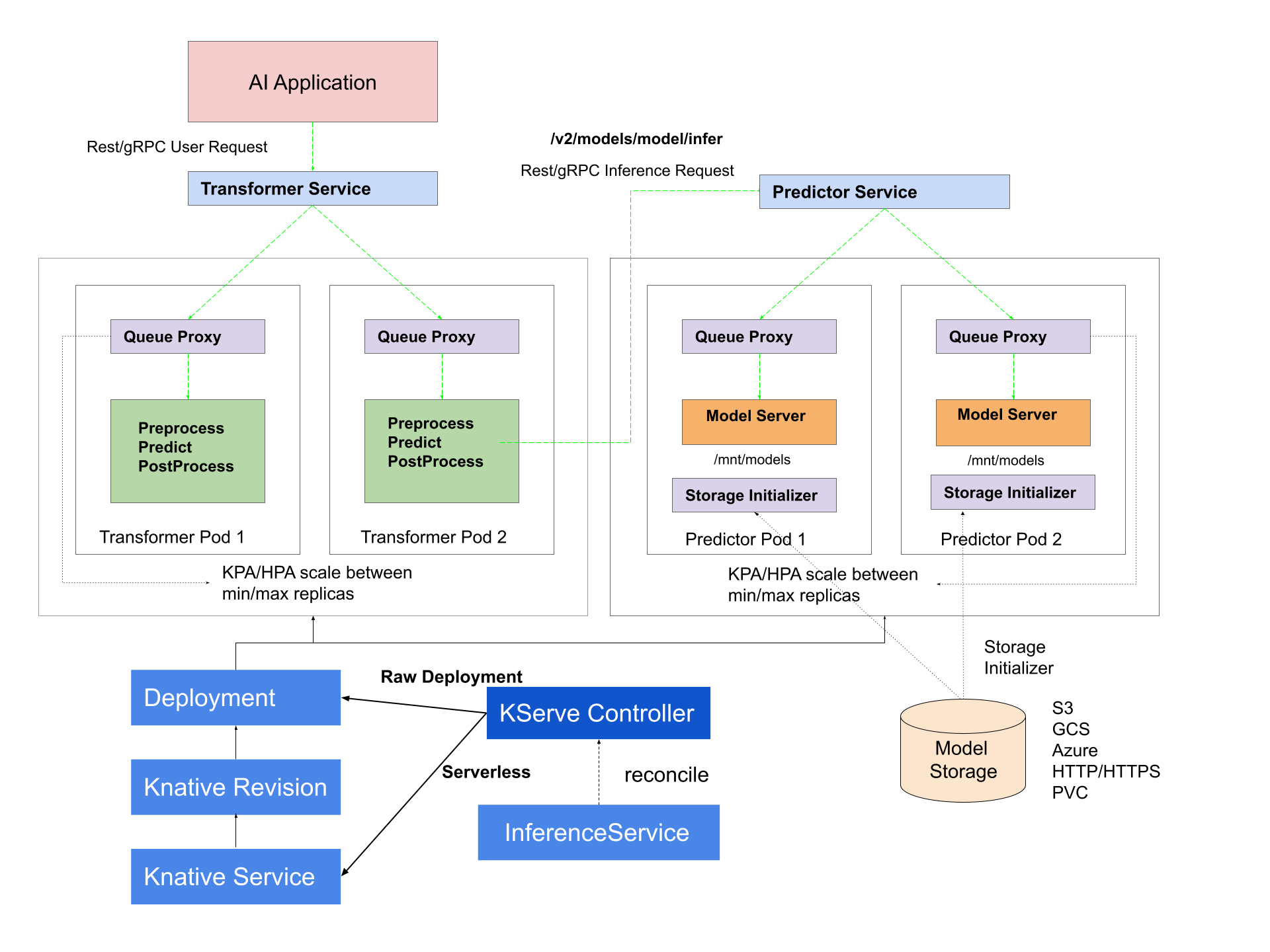 在 Kserve 中,主要组件为三个:Predictor、Transformer和Explainer。组件的作用可以看官网文档。
在 Kserve 中,主要组件为三个:Predictor、Transformer和Explainer。组件的作用可以看官网文档。
reconcilers := []components.Component{}
if deploymentMode != constants.ModelMeshDeployment {
reconcilers = append(reconcilers, components.NewPredictor(r.Client, r.Clientset, r.Scheme, isvcConfig, deploymentMode))
}
if isvc.Spec.Transformer != nil {
reconcilers = append(reconcilers, components.NewTransformer(r.Client, r.Clientset, r.Scheme, isvcConfig, deploymentMode))
}
if isvc.Spec.Explainer != nil {
reconcilers = append(reconcilers, components.NewExplainer(r.Client, r.Clientset, r.Scheme, isvcConfig, deploymentMode))
}
for _, reconciler := range reconcilers {
result, err := reconciler.Reconcile(ctx, isvc)
if err != nil {
r.Log.Error(err, "Failed to reconcile", "reconciler", reflect.ValueOf(reconciler), "Name", isvc.Name)
r.Recorder.Eventf(isvc, corev1.EventTypeWarning, "InternalError", err.Error())
if err := r.updateStatus(ctx, isvc, deploymentMode); err != nil {
r.Log.Error(err, "Error updating status")
return result, err
}
return reconcile.Result{}, errors.Wrapf(err, "fails to reconcile component")
}
if result.Requeue || result.RequeueAfter > 0 {
return result, nil
}
}Predict
1. 初始化与变量定义
在 Reconcile 方法开头,代码通过定义多个局部变量来为后续操作做准备,例如:
container:后续将表示预测服务中运行的容器配置。podSpec:定义 pod 中所有容器等配置。- 与 worker 相关的变量(例如
workerPodSpec、workerObjectMeta),用于支持多节点部署。 sRuntime和一系列标签、注解变量,用于从 ServingRuntime 中获取默认配置。
关键点在于根据 InferenceService 的定义来决定是否启用多节点模式(multiNodeEnabled),例如通过判断 isvc.Spec.Predictor.WorkerSpec 是否为 nil。
2. 处理用户自定义注解和标签
接着代码会过滤 InferenceService 的注解,避免出现被拒绝的服务注解。通过调用类似 utils.Filter 方法,将只保留允许的注解。随后,还会调用一些辅助函数:
addLoggerAnnotationsaddBatcherAnnotationsaddStorageSpecAnnotationsaddAgentAnnotations
这些步骤确保在后续调和过程中,pod 与容器能够正确挂载所需的数据和 agent。
3. 模型配置与 ServingRuntime 的选择
如果在 InferenceService 中定义了 Model 配置,Reconcile 会走一条针对模型部署的路径。主要流程如下:
- 验证与获取 ServingRuntime
如果用户指定了 runtime,则调用isvcutils.GetServingRuntime去获取对应的 ServingRuntime 配置;如果未指定,则使用GetSupportingRuntimes获取支持所选框架的 runtime 列表,并选择第一个支持版本。 - 合并配置
通过isvcutils.MergeServingRuntimeAndInferenceServiceSpecs将 ServingRuntime 中预设的容器或 pod 配置和用户自定义的配置合并。这一步确保配置灵活,同时也保持 runtime 的默认配置不被用户配置完全覆盖。 - 替换占位符和更新镜像
调用ReplacePlaceholders用 InferenceService 的元数据替换 container 中的占位符;随后调用UpdateImageTag根据 GPU 或 runtime 版本来更新镜像标签。
这些步骤最终确定了 podSpec 的结构与容器镜像的配置信息,同时也对 protocol version 做了默认处理。
获取到的runtime可能如下:
# kubectl describe ClusterServingRuntime kserve-sklearnserver
Name: kserve-sklearnserver
Namespace:
Labels: <none>
Annotations: <none>
API Version: serving.kserve.io/v1alpha1
Kind: ClusterServingRuntime
Metadata:
Creation Timestamp: 2025-03-08T09:50:00Z
Generation: 4
Resource Version: 1153764
UID: 747d6b02-a963-45a9-9635-b54f50be3ce9
Spec:
Annotations:
prometheus.kserve.io/path: /metrics
prometheus.kserve.io/port: 8080
Containers:
Args:
--model_name={{.Name}}
--model_dir=/mnt/models
--http_port=8080
Image: crpi-h5pf7vq24twssgqd.cn-beijing.personal.cr.aliyuncs.com/lizhuo1/sklearnserver
Name: kserve-container
Resources:
Limits:
Cpu: 1
Memory: 2Gi
Requests:
Cpu: 1
Memory: 2Gi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Privileged: false
Run As Non Root: true
Protocol Versions:
v1
v2
Supported Model Formats:
Auto Select: true
Name: sklearn
Priority: 1
Version: 1
Events: <none>在 Predictor 的调和过程中,当 InferenceService 中指定了 Model 配置时,会从 ServingRuntime 中获取默认的容器配置和 PodSpec 信息,然后结合用户在 InferenceService 里指定的覆盖配置。这个过程的关键就在于调用了 MergeServingRuntimeAndInferenceServiceSpecs 函数。
MergeServingRuntimeAndInferenceServiceSpecs 主要完成下面两个任务:
-
合并容器配置
从 ServingRuntime 传入的容器列表中找到目标容器(通过 targetContainerName,比如 “inferenceservice-container”),再将该容器配置与用户提供的预测容器配置进行合并。合并后的结果既保留了 ServingRuntime 的默认设置,也允许用户对部分字段进行覆盖。 -
合并 Pod 规格
将 ServingRuntime 中定义的 PodSpec(一般包含 NodeSelector、Affinity、Volumes 等信息)与用户通过 InferenceService 指定的 PodSpec 做整合,得到最终要部署的 PodSpec。
下面结合代码逐步分析其实现细节:
// 查找 ServingRuntime 中目标容器的索引
var containerIndexInSR = -1
for i := range srContainers {
if srContainers[i].Name == targetContainerName {
containerIndexInSR = i
break
}
}
if containerIndexInSR == -1 {
// 未找到则更新状态,返回错误,确保调和流程能及时反馈问题
errMsg := fmt.Sprintf("failed to find %s in ServingRuntime containers", targetContainerName)
isvc.Status.UpdateModelTransitionStatus(v1beta1.InvalidSpec, &v1beta1.FailureInfo{
Reason: v1beta1.InvalidPredictorSpec,
Message: errMsg,
})
return 0, nil, nil, errors.New(errMsg)
}这里的核心思路是:
- 遍历传入的 ServingRuntime 容器列表(srContainers),寻找名字与 targetContainerName 匹配的容器。
- 如果找不到,则立即用 isvc.Status 记录错误状态,并返回错误,防止后续执行产生不可预期的问题。
接下来就是进行容器合并的过程。
mergedContainer, err := MergeRuntimeContainers(&srContainers[containerIndexInSR], &isvcContainer)
if err != nil {
errMsg := fmt.Sprintf("failed to merge container. Detail: %s", err)
isvc.Status.UpdateModelTransitionStatus(v1beta1.InvalidSpec, &v1beta1.FailureInfo{
Reason: v1beta1.InvalidPredictorSpec,
Message: errMsg,
})
return 0, nil, nil, errors.New(errMsg)
}在这里调用了 MergeRuntimeContainers 函数,它利用 Kubernetes 的战略合并补丁(StrategicMergePatch)技术:
- 首先将 ServingRuntime 的容器(默认配置)和 InferenceService 里用户定义的容器(覆盖配置)分别 Marshal 成 JSON;
- 通过 StrategicMergePatch 将两者合并,生成一个新的容器配置;
- 需要注意的是,由于 JSON Patch 的特性,原来 ServingRuntime 中的 args 被覆盖,而这里通过 append 两边 args 实现了合并(即:先保留 runtime args,再拼接覆盖配置中的 args)。
合并容器的目的是确保最终容器既符合 ServingRuntime 的期望,又能满足用户的定制化配置。
紧接着对 PodSpec 的合并进行处理:
mergedPodSpec, err := MergePodSpec(&srPodSpec, &isvcPodSpec)
if err != nil {
errMsg := fmt.Sprintf("failed to consolidate serving runtime PodSpecs. Detail: %s", err)
isvc.Status.UpdateModelTransitionStatus(v1beta1.InvalidSpec, &v1beta1.FailureInfo{
Reason: v1beta1.InvalidPredictorSpec,
Message: errMsg,
})
return 0, nil, nil, errors.New(errMsg)
}这里调用了 MergePodSpec:
- 同样采用 JSON marshal 与 StrategicMergePatch 的方式,将 ServingRuntime 提供的 PodSpec(例如 NodeSelector、Affinity 等)与 InferenceService 中指定的 PodSpec 做整合;
- 最终的合并结果可以保证部署时能够兼容 runtime 的调优与用户的特殊需求。
最后,该函数返回三个重要值:
- containerIndexInSR:目标容器在 ServingRuntime 内的索引,后续可能用于在最终的 podSpec 中定位顺序;
- mergedContainer:合并后的容器配置;
- mergedPodSpec:合并后的 PodSpec。
这些返回值随后在 Predictor 的 Reconcile 方法中被使用,用于构造完整的 Pod 组件定义,同时还会进行后续的占位符替换、镜像 tag 更新等工作。
4. Service 与 ControllerOwnerReference 的设置
在获取容器配置后,Reconcile 方法中会为服务对象确定名称。
- 如果使用原生 Kubernetes 部署(raw deployment),则需要查找是否已经存在默认的 Service,决定 service 的名字。
- 否则,则使用 Knative 的 Service 对象,并利用
controllerutil.SetControllerReference来确保 controller 与服务对象之间的引用关系正确。
此外,通过对 labels 与 annotations 的 union 操作,将来自 InferenceService、ServingRuntime、以及用户指定的配置整合到最终的 objectMeta 中。
5. 多节点(multi-node)处理
当检测到多节点部署(即 isvc.Spec.Predictor.WorkerSpec != nil)时,代码会调用 multiNodeProcess 方法。
- 该方法主要校验 ServingRuntime 是否支持 worker 配置。
- 同时,会合并 worker 容器配置与 pod 配置,并设置一些必须的环境变量,如 PipelineParallelSize 和 TensorParallelSize。
- 此外,通过调用
isvcutils.AddEnvVarToPodSpec为主容器与 worker 容器添加环境变量,这些变量用于后续的模型调度与并行计算。
6. 最终资源创建与状态更新
根据部署模式不同(raw 或 Knative),Reconcile 分为两大分支:
- Raw 部署:调用
raw.NewRawKubeReconciler创建 RawKubeReconciler 实例,并通过它来创建 Deployment、Service 以及 autoscaler 对象。调和成功后,通过isvc.Status.PropagateRawStatus来更新 InferenceService 的状态。 - Knative 部署:调用
knative.NewKsvcReconciler创建对应的 reconciler,设置 controller reference 后调用其 Reconcile 方法,最终利用isvc.Status.PropagateStatus将状态同步到 InferenceService 资源。
最后,通过 isvcutils.ListPodsByLabel 查询 pod 状态,并调用 PropagateModelStatus 判断是否需要重试、或者返回成功结果。
补充:KsvcReconciler
KsvcReconciler 主要负责管理 Knative Service 对象的生命周期。在 Predictor 调和过程中,当采用 Knative 部署模式时,KsvcReconciler 用来将调和后的服务对象(包含容器配置、流量分配、滚动更新策略等)与集群中已有的 Knative Service 对象进行对比,并执行更新操作。其调和过程确保:
- 如果资源对象没有改变,就不进行更新;
- 如果存在差异,则协调修改,并利用重试机制处理并发冲突;
- 当资源不存在时,会创建新的 Knative Service。
在 NewKsvcReconciler 中,会调用 createKnativeService,结合组件元数据(Metadata)、扩展参数(例如最小/最大副本数、流量权重、滚动更新等)以及 PodSpec 来生成一个“期望状态”的 Knative Service 对象。代码片段如下:
func createKnativeService(componentMeta metav1.ObjectMeta,
componentExtension *v1beta1.ComponentExtensionSpec,
podSpec *corev1.PodSpec,
componentStatus v1beta1.ComponentStatusSpec,
disallowedLabelList []string,
) *knservingv1.Service {
// 根据组件元数据和扩展参数填充 annotations,比如最小/最大副本、缩放目标、指标等
annotations := componentMeta.GetAnnotations()
// 设置 MinScale 和 MaxScale 等
...
// 从组件元数据中提取出需要移到 Service 对象的 annotations
ksvcAnnotations := make(map[string]string)
for ksvcAnnotationKey := range managedKsvcAnnotations {
if value, ok := annotations[ksvcAnnotationKey]; ok {
ksvcAnnotations[ksvcAnnotationKey] = value
delete(annotations, ksvcAnnotationKey)
}
}
// 构造 traffic target,根据 canary 流量分配逻辑进行蓝绿部署或分流策略设置
trafficTargets := []knservingv1.TrafficTarget{}
if componentExtension.CanaryTrafficPercent != nil && componentStatus.LatestRolledoutRevision != "" {
// 当设置了 canary 流量百分比时,最新修订版获取指定流量,其余流量分给先前版本
...
} else {
// 普通发布:全部流量指向最新版本
latestTarget := knservingv1.TrafficTarget{
LatestRevision: proto.Bool(true),
Percent: proto.Int64(100),
}
if value, ok := annotations[constants.EnableRoutingTagAnnotationKey]; ok && value == "true" {
latestTarget.Tag = "latest"
}
trafficTargets = append(trafficTargets, latestTarget)
}
// 过滤不允许的标签
labels := utils.Filter(componentMeta.Labels, func(key string) bool {
return !utils.Includes(disallowedLabelList, key)
})
// 调用构造函数生成 Knative Service 对象
service := &knservingv1.Service{
ObjectMeta: metav1.ObjectMeta{
Name: componentMeta.Name,
Namespace: componentMeta.Namespace,
Labels: componentMeta.Labels,
Annotations: ksvcAnnotations,
},
Spec: knservingv1.ServiceSpec{
ConfigurationSpec: knservingv1.ConfigurationSpec{
Template: knservingv1.RevisionTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: labels,
Annotations: annotations,
},
Spec: knservingv1.RevisionSpec{
TimeoutSeconds: componentExtension.TimeoutSeconds,
ResponseStartTimeoutSeconds: componentExtension.TimeoutSeconds,
ContainerConcurrency: componentExtension.ContainerConcurrency,
PodSpec: *podSpec,
},
},
},
RouteSpec: knservingv1.RouteSpec{
Traffic: trafficTargets,
},
},
}
return service
}这一部分的工作是将所有调和过程中生成的配置(包括 PodSpec 和流量策略)整合到目标 Service 对象中。
KsvcReconciler 的 Reconcile 方法负责实现 Knative Service 对象的最终更新操作。其核心逻辑如下:
func (r *KsvcReconciler) Reconcile(ctx context.Context) (*knservingv1.ServiceStatus, error) {
desired := r.Service // 期望状态
existing := &knservingv1.Service{}
err := retry.RetryOnConflict(retry.DefaultBackoff, func() error {
log.Info("Updating knative service", "namespace", desired.Namespace, "name", desired.Name)
// 先获取最新的 Service 对象,确保是最新版本,防止 stale 状态覆盖最新的变动
if err := r.client.Get(ctx, types.NamespacedName{Name: desired.Name, Namespace: desired.Namespace}, existing); err != nil {
return err
}
// 为更新操作设置 ResourceVersion
desired.ResourceVersion = existing.ResourceVersion
// 对于不可变的 annotation,保持原有值(例如 CreatorAnnotation 和 UpdaterAnnotation)
desired.Annotations[knserving.CreatorAnnotation] = existing.Annotations[knserving.CreatorAnnotation]
desired.Annotations[knserving.UpdaterAnnotation] = existing.Annotations[knserving.UpdaterAnnotation]
// 进行 Dry-Run 更新,将默认值等注入到对象中,防止产生无效的差异
if err := r.client.Update(ctx, desired, client.DryRunAll); err != nil {
if !apierr.IsConflict(err) {
log.Error(err, "Failed to perform dry-run update of knative service", "service", desired.Name)
}
return err
}
// 对比 desired 与 existing 服务,调用 reconcileKsvc 来修正需要变更的部分
if err := reconcileKsvc(desired, existing); err != nil {
return err
}
// 真正的更新操作
return r.client.Update(ctx, existing)
})
// 若更新出错,且目标 Service 不存在,则进行创建操作。
if err != nil {
if apierr.IsNotFound(err) {
log.Info("Creating knative service", "namespace", desired.Namespace, "name", desired.Name)
return &desired.Status, r.client.Create(ctx, desired)
}
return &existing.Status, errors.Wrapf(err, "fails to reconcile knative service")
}
return &existing.Status, nil
}这里的关键点包括:
- 获取最新对象和设置 ResourceVersion:在实际更新前先用 GET 取得最新的 Knative Service,然后用其 ResourceVersion 确保更新操作不会因版本冲突失败。
- Dry-Run 更新:使用 Dry-Run 模式对 desired 对象进行更新操作,以填充默认值并规避因默认值导致的 diff,从而防止无意义的更新。
- 差异比对与修正:调用 reconcileKsvc 函数,对比 desired 与 existing 对象(例如对象元数据 Label、Annotations 以及 Spec 中的 ConfigurationSpec 和 RouteSpec),将需要更新的部分同步回 existing 对象。
- 重试机制:整个更新操作包装在 retry.RetryOnConflict 中,能够自动处理因并发更新产生的冲突,保证调和操作的最终成功。
在 reconcileKsvc 中,通过 kmp.SafeDiff 计算两者的差异信息,然后将 desired 对象的更新内容覆盖到 existing 对象中,再提交更新:
func reconcileKsvc(desired *knservingv1.Service, existing *knservingv1.Service) error {
if semanticEquals(desired, existing) {
return nil
}
// 通过 kmp.SafeDiff 得到配置差异,日志记录方便问题排查
diff, err := kmp.SafeDiff(desired.Spec.ConfigurationSpec, existing.Spec.ConfigurationSpec)
if err != nil {
return errors.Wrapf(err, "failed to diff knative service configuration spec")
}
log.Info("knative service configuration diff (-desired, +observed):", "diff", diff)
// 更新 existing 对象内的 Spec、Labels 和部分 Annotations
existing.Spec.ConfigurationSpec = desired.Spec.ConfigurationSpec
existing.ObjectMeta.Labels = desired.ObjectMeta.Labels
existing.Spec.Traffic = desired.Spec.Traffic
...
return nil
}semanticEquals 则通过 DeepEqual 比较 desired 与 existing 的 Spec、Labels 和 Annotations,决定是否需要更新处理。
KsvcReconciler 的调和过程在 Knative 部署模式下主要负责以下几个方面:
- 构造 Desired 对象:根据 Predictor 调和过程中生成的 PodSpec、流量目标、缩放参数等信息,生成期望的 Knative Service 对象。
- 智能对比与更新:先通过 Dry-Run 获取默认值,然后比对 desired 与现有对象,修正需要的差异,再进行资源更新。通过重试机制处理更新冲突。
- 创建和回滚:当 Knative Service 不存在时,自动执行创建操作;而在更新过程中,如果发生版本冲突也能够自动重试,以确保集群状态与期望状态保持一致。
这样的设计既保证了 Knative Service 对象的配置准确性,也使得调和操作在面对并发更新和默认值注入时更为稳定和可靠。
Reconcile modelConfig
updateStatus
func (r *InferenceServiceReconciler) updateStatus(ctx context.Context, desiredService *v1beta1.InferenceService,
deploymentMode constants.DeploymentModeType,
) error {
existingService := &v1beta1.InferenceService{}
namespacedName := types.NamespacedName{Name: desiredService.Name, Namespace: desiredService.Namespace}
if err := r.Get(ctx, namespacedName, existingService); err != nil {
return err
}
wasReady := inferenceServiceReadiness(existingService.Status)
if inferenceServiceStatusEqual(existingService.Status, desiredService.Status, deploymentMode) {
// If we didn't change anything then don't call updateStatus.
// This is important because the copy we loaded from the informer's
// cache may be stale and we don't want to overwrite a prior update
// to status with this stale state.
} else if err := r.Status().Update(ctx, desiredService); err != nil {
r.Log.Error(err, "Failed to update InferenceService status", "InferenceService", desiredService.Name)
r.Recorder.Eventf(desiredService, corev1.EventTypeWarning, "UpdateFailed",
"Failed to update status for InferenceService %q: %v", desiredService.Name, err)
return errors.Wrapf(err, "fails to update InferenceService status")
} else {
// If there was a difference and there was no error.
isReady := inferenceServiceReadiness(desiredService.Status)
isReadyFalse := inferenceServiceReadinessFalse(desiredService.Status)
if wasReady && isReadyFalse { // Moved to NotReady State
r.Recorder.Eventf(desiredService, corev1.EventTypeWarning, string(InferenceServiceNotReadyState),
fmt.Sprintf("InferenceService [%v] is no longer Ready because of: %v", desiredService.GetName(), r.GetFailConditions(desiredService)))
} else if !wasReady && isReady { // Moved to Ready State
r.Recorder.Eventf(desiredService, corev1.EventTypeNormal, string(InferenceServiceReadyState),
fmt.Sprintf("InferenceService [%v] is Ready", desiredService.GetName()))
}
}
return nil
}在 kserve 的控制器中,状态更新是调和流程的关键环节。updateStatus 函数负责对比当前集群中已有的状态与期望状态,然后在有差异时更新状态,同时通过事件记录通知用户服务状态的变化。
函数开始时,使用给定的 desiredService 对象(代表调和后期望的状态)构造 namespacedName,然后通过 r.Get 获取最新的 InferenceService 对象。这一步确保我们工作在最新的资源快照上,避免因 informer 缓存滞后而覆盖其他并发更新。取得现有状态后,通过调用 inferenceServiceReadiness 函数检查该对象是否“就绪”,并将这一结果记录在 wasReady 变量中。
接下来,调用 inferenceServiceStatusEqual 将现有状态与期望状态进行对比。如果两个状态在逻辑上相同,函数不会继续更新;这样做的核心目的是避免不必要的 API 更新操作,因为 informer 缓存中的数据可能已经过时,一旦更新可能导致正确的状态回退。这种设计可以防止因为 stale 对象覆盖最新修改。
当对比后发现状态确实发生变化,则使用 r.Status().Update 更新整个 desiredService 对象。如果更新操作返回错误,则记录错误日志,同时通过事件记录器(Recorder)生成一个 Warning 类型的事件,向外部用户告知状态更新失败。
更新成功后,函数会再次判断当前状态是否进入了一个重要的转换(例如从 Ready 状态切换到非 Ready 状态,或从非 Ready 变为 Ready)。为此,它分别调用 inferenceServiceReadiness(desiredService.Status) 和 inferenceServiceReadinessFalse(desiredService.Status) 来获取最新的“就绪”判断。如果之前 wasReady 为真,而现在状态表明不就绪,则记录一个警告事件,提醒用户服务失去就绪状态,并附上失败原因(通过 GetFailConditions 辅助函数将所有不满足条件的原因串联在一起);反之,如果之前不就绪而现在变为就绪,则生成一个正常事件通知用户服务已恢复。
这种状态变化通知机制在集群中非常重要,因为它不仅仅是短暂的状态同步,而是向用户和其他系统传达服务健康状态的重要信息。这段代码既保证了 Kubernetes API 的幂等性(只有在状态真正变化时才更新),同时利用事件记录器,使得运维人员能够及时查看 InferenceService 状态的历史变化,从而有助于故障排查。