这篇论文《Understanding World or Predicting Future? A Comprehensive Survey of World Models》不仅仅是一篇综述,它实际上是在为当前人工智能最混乱的一个概念——世界模型(World Model)——划定边界和定义 。
概念溯源与“大分裂”
要弄懂大佬们在争什么,我们首先得意识到“World Model(世界模型)”并不是一个随大模型爆发而新造的词汇,而是一个在认知科学和 AI 领域纠缠了半个世纪的古老概念。这篇综述非常敏锐地抓住了当前学术界的痛点:大家都在说 World Model,但大家指的可能根本不是同一个东西。
早在 1970 年代,Marvin Minsky 就提出了 Frame System 理论,试图用结构化的知识来捕捉世界运作的规律 。但这个概念真正被现代深度学习“复活”,要归功于 Ha 和 Schmidhuber 在 2018 年的开创性工作 。他们借用了心理学中“心智模型(Mental Models)”的概念,认为人类之所以能从容应对复杂的世界,是因为我们在大脑中建立了一个外部世界的微缩版本。
这个微缩版本并不是对现实世界 1:1 的像素级复刻,而是一种抽象的、简化的内部表征 。就像我们不需要记住那张椅子的每一个原子结构,只需要记住“这把椅子能坐、它在那里”这个抽象状态即可。在这个阶段,学术界的核心共识是:世界模型是一个在潜空间(Latent Space) 中运作的压缩器,它过滤掉冗余细节,只保留对决策有用的核心信息 。
随着 2022 年 Yann LeCun 提出 JEPA 架构,以及 2024 年 Sora 的横空出世,学术界迅速分化为两个对立又互补的阵营,这正是这篇综述的核心论点:World Model 到底是为了理解当下的机制,还是为了预测未来的表象? 。

理解派 以 Yann LeCun 为代表。如图左侧所示,他们坚持认为世界模型必须包含对因果和物理机制的深层理解 。LeCun 提出的 JEPA (Joint Embedding Predictive Architecture) 强调,一个真正智能的大脑(System 2)应该能够超越直觉反应,在抽象空间中推演未来的可能性,从而指导当前的决策 。对这一派来说,模型不需要生成一段逼真的视频,它只需要在“脑海中”推演出如果我做这个动作,结果是好是坏即可 。
预测派(Predicting) 则以 OpenAI 的 Sora 等视频生成模型为代表。如图右侧所示,这一派的哲学更加暴力美学:Simulation(模拟)即理解 。他们认为,如果一个模型能够生成符合物理定律(如光影反射、物体运动)的高质量视频,那么它一定在某种程度上已经内化了世界的物理法则 。这一派倾向于通过 Next-Token Prediction(预测下一帧/下一个词)来逼近对世界的建模,侧重于视觉上的“真实感”和对未来状态的具象化模拟 。
内隐表征学派(理解派)
欢迎进入“深度思考者”的世界。这一流派由图灵奖得主 Yann LeCun 领衔,其核心哲学可以概括为一句话:世界模型的本质是决策的大脑,而非渲染的显卡。 他们认为,一个真正的智能体不需要画出逼真的画面,只需要在脑海中清楚地知道“后果”即可。

这一派早期的代表作是 Dreamer 系列(如 DreamerV3 )。试想一下,如果你想学会滑雪,你不需要真的摔断腿一百次。你可以在脑海中(潜在空间 Latent Space)模拟滑雪的过程:重心前倾会加速,后仰会摔倒。这正是 Model-based Reinforcement Learning (MBRL) 的精髓 。
在这个框架下,世界模型起到了“模拟器”的作用。智能体在一个由神经网络构建的虚拟环境模型中进行大量的试错训练 。这个模型不需要渲染出每一片雪花的纹理,它只需要在抽象的数学空间里准确预测出“状态(State)”的流转 。一旦在“梦境”中训练好了策略,再将其迁移到现实世界,就能实现极高的样本效率,即用极少的数据学会复杂的技能 。
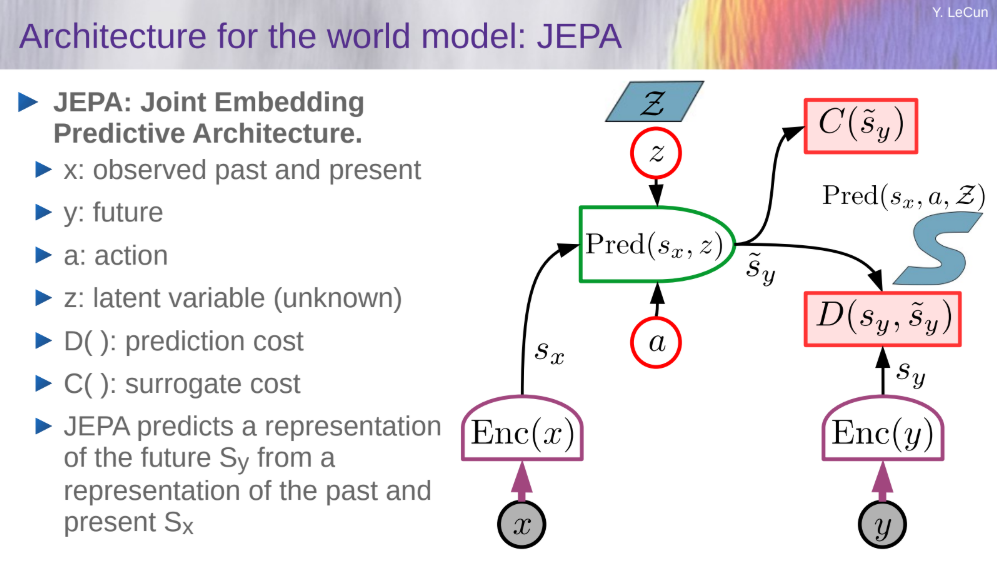
Yann LeCun 在 2022 年提出的 JEPA (Joint Embedding Predictive Architecture) 是这一流派的集大成者 。他敏锐地指出了“预测像素”的致命缺陷:世界充满了无关紧要的随机细节。例如,当你在开车时,路边树叶随风摆动的精确像素变化是完全随机且不可预测的,但这对于“是否刹车”这个决策毫无影响。
因此,JEPA 坚决反对生成像素。它引入了一个 “联合嵌入(Joint Embedding)” 的机制,强制模型在高度抽象的特征空间中进行预测 。在这个空间里,树叶的摆动被过滤掉了,只保留了“前方有障碍物”这样的核心语义信息。这使得模型能够忽略冗余的噪音,专注于因果逻辑的推演。
这一流派与认知科学中的 System 1 (快思考) 与 System 2 (慢思考) 可以联系起来 。System 1 是直觉反应,比如看到球飞过来下意识躲避;而 System 2 则是深思熟虑,比如下棋时推演未来十步的棋局。
在 LeCun 的架构中,世界模型正是那个负责 System 2 的核心组件 。它允许智能体在采取行动之前,先在内部模型中进行多步推理(Reasoning),模拟不同决策的未来分支,评估哪条路径回报最高,然后再执行。这种能力被称为“规划(Planning)”,是通往通用人工智能(AGI)的关键一步 。
未来预测学派 (预测派)
如果说 LeCun 是在教机器“冥想”,那么 OpenAI 和 Sora 团队就是在教机器“造梦”。这一流派的核心哲学极其直观:“What I cannot create, I do not understand” (我不能创造的,我就不理解)。 反过来说,如果通过海量数据训练,模型能够生成出完美符合物理规律的视频,那么它一定在某种层面上“涌现”出了对世界的理解。
Sora类模型其实可以被定义为“世界模拟器(World Simulator)”,而不仅仅是一个视频剪辑工具 。这一学派认为,传统的“理解”过于抽象,无法验证。既然我们生活在一个视觉主导的三维世界里,那么能够预测像素流的演变,就是掌握了世界模型的铁证。
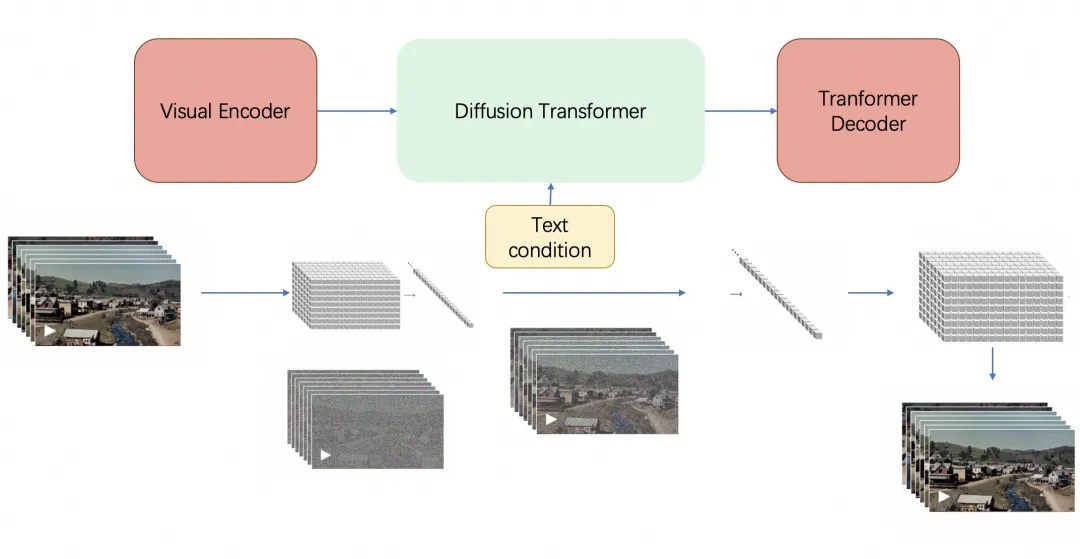
为了实现这一点,这些模型(包括 Sora, Gen-2, Keling 等)利用了 Diffusion Model(扩散模型)和 Transformer 的结合 。它们不仅仅是在处理静态图像,而是在学习时空连贯性。这意味着,当模型生成一个“玻璃杯掉落”的视频时,它并不是在机械地拼接图片,而是在潜意识里遵循了重力加速度、玻璃破碎的散射以及光影在碎片上的反射规则 。这种对物理定律的隐式习得,正是这一流派引以为傲的资本——它们声称自己没有被灌输牛顿定律,却“看懂”了牛顿定律。
但这还不够。单纯生成视频只能算是在看电影(Passive),真正的世界模型必须允许你进入其中(Interactive)。综述中特别提到了 UniSim 和 Genie 这样的工作,它们标志着这一流派的进阶 。
这些被称为 “具身环境(Embodied Environment)” 的模型,不再仅仅接受文本提示(Prompt),而是开始接受“动作(Action)”作为输入 。例如,在 UniSim 中,你可以输入一个由机械臂执行的动作指令,模型就会生成该动作发生后的视频反馈。这种机制将视频生成模型变成了一个可交互的虚拟游戏引擎。对于机器人训练来说,这意味着你可以用生成的视频来替代昂贵的现实世界试错,让 AI 在一个由 AI 创造的逼真梦境中通过第一人称视角学习如何与世界互动 。
一些争议
虽然视频看起来极其逼真,但模型究竟是学会了物理定律,还是仅仅记住了像素排列的统计规律?
尽管 Sora 等模型生成的视频在视觉上效果已经很不错了,但研究人员发现,一旦涉及到精确的物理交互,这些模型经常“露馅”。综述中明确指出,Sora 经常无法始终如一地复现正确的物理定律,例如物体在不同受力下的行为、流体动力学甚至基本的光影互动 。这种现象被称为 “物理幻觉” 。
这些模型往往是在做“基于案例(Case-based)”的泛化,而不是“基于规则(Rule-based)”的泛化。换句话说,模型并没有真正推导出 这样的通用公式,它只是在训练数据中见过无数次类似的场景,从而“背”下了大概的样子。一旦遇到训练数据分布之外的复杂组合场景,它的表现就会迅速崩塌。这意味着,目前的视频世界模型可能只是一个高配版的“图形记忆库”,而非真正的物理模拟器。
真正的世界模型必须具备回答“What If(如果……会怎样)”的能力,这被称为反事实推理 。例如,“如果我没有踩刹车,车会撞上那棵树吗?”这是人类规划未来、避免危险的基础。
然而,目前的视频生成模型大多是“被动”的。Sora 只能根据给定的初始状态生成一段视频,却很难精确地干预其中的因果链条,或者在保持其他条件不变的情况下改变某个特定变量 。由于缺乏这种主动干预和因果推演的能力,它们在自动驾驶等需要处理极度罕见边缘情况的领域,其实用性依然受到严峻挑战 。
为了解决纯数据驱动模型的“智商”瓶颈,综述指出了一个非常有前景的混合路径:将显式的物理引擎与隐式的生成模型结合 。
例如,Genesis 和 PhysGen 这样的系统展示了这种可能性 。它们不再单纯依赖神经网络去“猜”物理规律,而是引入了一个通用的物理引擎核心来处理刚体碰撞、重力等硬规则,然后利用生成式模型来渲染逼真的纹理和细节。这种“理性(物理引擎)+ 感性(生成模型)”的结合,既保证了物理的正确性,又保留了视觉的真实感,很可能是通往真正 World Model 的必经之路。