基本想法
这一节的核心是回答两个问题:我们为什么要做主成分分析?它究竟在做什么?
1. 解决“变量相关性”带来的分析难题
- 书中所述:“数据的变量之间可能存在相关性,以致增加了分析的难度。”
- 假设一个数据集,记录了中学生的身高(厘米)、体重(公斤)和立定跳远成绩(米)。这三个变量很可能不是独立的。身高越高、体重越重的学生,可能跳得更远(也可能跳不远,但它们之间存在某种关系)。如果我们直接用这三个相关的变量去建模,信息是有冗余的。比如,身高和体重可能共同反映了一个更本质的特征,不妨称之为“身体素质”。
- PCA的目标:我们希望能找到一个新的变量,比如就叫“身体素质综合得分”(),它是一个由身高、体重、跳远成绩线性组合而成的新变量。这个新变量应该尽可能多地包含原来三个变量中的信息。如果一个新变量不够,我们就找第二个、第三个,但要求这些新变量之间互相独立、没有冗余信息。这就是书中所说的“由少数不相关的变量来代替相关的变量”。
2. 坐标系旋转与最大方差
在《机器学习方法》中,李航老师用了一个非常精彩的类比:“主成分分析等价于进行坐标系旋转变换”。
-
原始数据:假设一下二维平面上有一堆散点,代表了学生的(身高,体重)数据。这些点可能呈一个斜向上的椭圆形分布,这正体现了身高和体重的相关性。我们用原始的坐标轴(身高轴,体重轴)来描述这些点。
-
PCA要做什么? PCA不改变数据点本身,而是试图找到一个新的坐标系来更好地描述这堆数据。
- 寻找新坐标轴 (主成分):
- 第一主成分 ():寻找一个新的坐标轴方向,当我们把所有数据点都投影到这个新轴上时,这些投影点的方差最大。在我们的例子里,这个新轴的方向大致就是椭圆的长轴方向。为什么是方差最大?因为方差衡量了数据的离散程度。方差最大的方向,就是数据变化最剧烈、包含信息最丰富的方向。
- 第二主成分 ():寻找第二个坐标轴方向。这个方向必须与第一个坐标轴正交(垂直),并且在所有与第一主成分正交的方向中,它同样使得数据投影后的方差最大。在我们的例子里,这基本就是椭圆的短轴方向。
- 以此类推,直到找到m个新的坐标轴。
- 寻找新坐标轴 (主成分):
-
“信息保持”与“降维”
- 信息保持:书中提到“要求能够保留数据中的大部分信息”。在PCA的语境下,“信息”由方差来度量。所有新坐标轴上的方差之和,等于原始坐标轴上的方差之和。这意味着坐标旋转本身没有丢失任何信息。
- 降维:但我们发现,第一个主成分(椭圆长轴)方向上的方差远大于第二个主成分(椭圆短轴)方向上的方差。这意味着,如果我们只保留第一主成分,用一个一维的“身体素质综合得分”来代替二维的(身高,体重),我们可能已经保留了原始数据95%的信息。这就是降维。
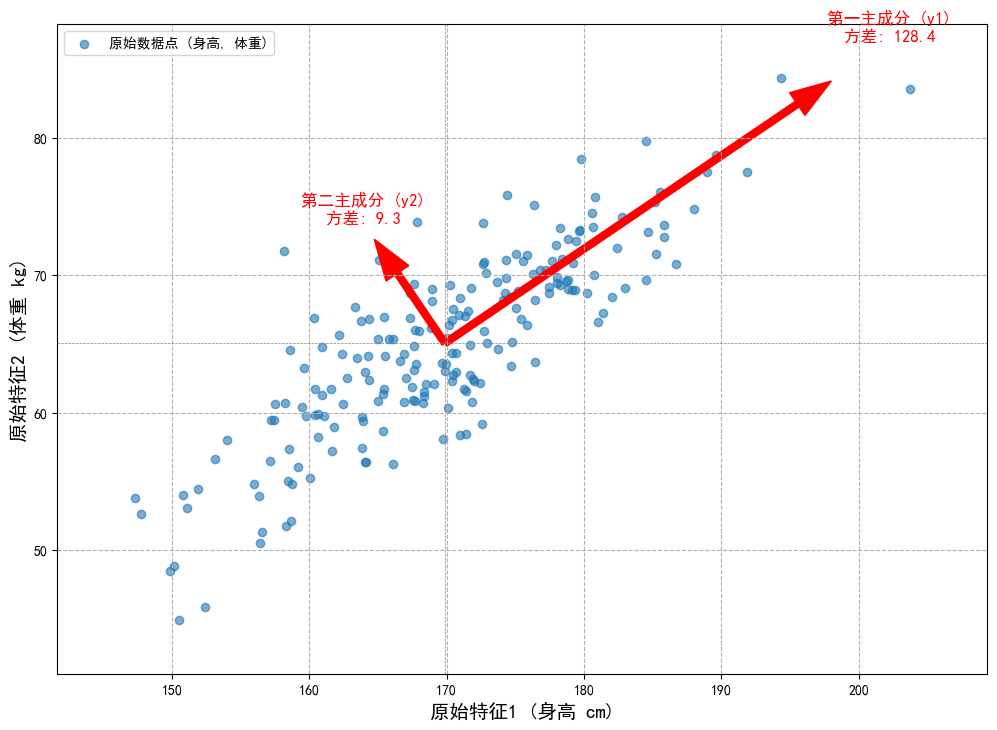
PCA的本质,是通过正交变换(坐标系旋转),将一组可能相关的原始变量,转化为一组线性无关的新变量(主成分)。这些新变量按照方差从大到小排列,使得我们可以用方差最大的前几个新变量来近似代表整个数据集,从而达到降维和去相关的目的。
定义和导出 (The “How”, in Math)
现在,我们把上面这些直观的想法,用精确的数学语言来描述。这就是书中16.1.2节的核心任务。
1. 数学设定
-
随机向量 :
这不再是具体的数据点了,而是代表一个包含 个随机变量的向量。比如, 可以是(身高, 体重, 跳远成绩)这三个随机变量的集合。
-
均值向量 :
这是随机向量 的期望值,包含了每个变量的平均值。
-
协方差矩阵 :
这是至关重要的概念。这是一个 的对称矩阵。
- 对角线元素 是第 个变量自身的方差,即 。
- 非对角线元素 是第 和第 个变量的协方差,即 。
- 协方差矩阵完美地描述了原始变量间的相关性。==我们的目标就是通过一个变换,得到一组新变量,使得它们的新协方差矩阵变成一个对角矩阵(即非对角线元素全为0,表示新变量间线性无关)。==
2. 线性变换
我们寻找的新变量 是原始变量 的线性组合。
写成向量形式就是:
- : 原始的 维随机向量。
- : 这是一个 维的系数向量或权重向量。它定义了一个方向。PCA的核心任务,就是要找到这一组最佳的 。
- : 变换后的新变量,是一个标量。它就是 在 方向上的投影(如果 是单位向量)。
3. 新变量的统计性质
一旦定义了变换 ,利用随机变量的性质,我们可以马上推导出新变量的期望、方差和协方差:
-
期望 (式16.2):
(因为期望是线性运算)
-
方差 (式16.3):
==这个公式是核心中的核心。它告诉我们,新变量的方差,完全由原始数据的协方差矩阵 和我们选择的方向 决定。 我们的目标就是最大化这个值!==
-
协方差 (式16.4):
这个公式衡量了任意两个新变量 和 之间的相关性。==我们的目标就是让这个值在 时等于0!==
4. 定义16.1 (总体主成分)
这个定义将我们前面所有的直观想法和数学推导,总结成了三条严格的规则。这三条规则合在一起,就构成了一个带约束的序贯优化问题。
-
条件(1):
- 数学意义: 系数向量 是单位向量,它的长度为1。
- 为什么需要这个条件? 如果没有这个约束,我们可以通过单纯地把 的所有元素乘以100,来让方差 变成原来的10000倍。这样最大化方差就没意义了。这个条件确保我们只关心方向,而不是向量的长度。
-
条件(2): 与 互不相关,即
- 数学意义: 根据式(16.4),这就等价于 。
- 直观联系: 这就是我们“新坐标轴要正交”这个思想在统计上的体现。注意,这里的正交是“关于 的正交”,它保证了新变量在统计意义上的线性无关。
-
条件(3): 方差最大, 是与 无关的方差最大者,以此类推。
- 这是一个逐级寻找(贪心)的过程:
-
求第一主成分 : 我们要求解的优化问题是:
-
求第二主成分 : 在所有与 不相关的线性变换中,找方差最大的。优化问题是:
-
求第 主成分 : 以此类推。
-
- 这是一个逐级寻找(贪心)的过程:
至此,“问题是什么” 已经定义得非常清楚了。接下来的内容,就是去 “如何求解” 这个优化问题了。而这个求解过程,将不可避免地与协方差矩阵 的特征值分解联系在一起。
核心:定理16.1 的证明
定理 16.1
设 是 维随机变量, 是 的协方差矩阵, 的特征值分别是 ,特征值对应的单位特征向量分别是 ,则 的第 主成分是
的第 主成分的方差是
即协方差矩阵 的第 个特征值。
定理内容简述: 这个定理告诉我们一个惊人的结论:==我们费尽心思定义的、通过“序贯最大化方差”得到的主成分,其方向向量 恰好就是协方差矩阵 的特征向量,而该主成分的方差 恰好就是对应的特征值 。==
这个定理把一个复杂的优化问题,转化成了一个我们非常熟悉的线性代数问题——求解矩阵的特征值和特征向量。
第一步:证明第一主成分
我们的目标是求解下面这个带约束的优化问题:
1. 构造拉格朗日函数 (Why Lagrange Multipliers?)
-
回顾:拉格朗日乘子法是解决“带等式约束的优化问题”的标准工具。它的核心思想是,将约束条件乘以一个拉格朗日乘子(比如 ),然后从目标函数中减去它,从而构造一个新的、无约束的拉格朗日函数。通过对这个新函数求导并令其为0,我们就能找到原问题的可能极值点。
-
我们的问题:
- 目标函数:
- 等式约束:
-
构造拉格朗日函数 :
2. 对 求导并令其为0 (The Calculus)
现在,我们将 看作是关于变量 的函数,并对它求梯度。这里需要用到两个矩阵求导的常用公式:
-
(当 是对称矩阵时,而在我们本次求解中 就是对称的)
-
-
求导过程:
-
令导数为0:
3. 解读结果
这个方程眼熟吗?这不就是线性代数中特征值和特征向量的定义!
- 是协方差矩阵 的一个特征值。
- 是与该特征值 对应的特征向量。
我们还没结束。我们要求的是目标函数 的最大值。我们来看看这个最大值是什么:
这说明,目标函数的值(也就是第一主成分的方差)就等于特征值 。为了让这个方差最大化,我们显然应该选择最大的那个特征值,我们称之为 。
妙!第一主成分 的系数向量 是协方差矩阵 的最大特征值 所对应的单位特征向量。第一主成分的方差就是 。
第二步:证明第二主成分
现在的问题变得更复杂了,我们有两个约束条件:
1. 简化约束2 (The Trick)
李航老师在书中用了一个非常巧妙的简化。让我们看看约束2:。
因为我们已经知道 是 关于 的特征向量,所以 。由于 是对称矩阵,它的转置等于自身 ()。所以,我们可以对 两边同时取转置: 。
现在把这个代入约束2:
由于 是最大特征值(通常大于0,除非数据完全没有变化),所以上式成立的唯一可能是:
这意味着,“新变量 和 线性无关”这个统计条件,等价于“方向向量 和 几何正交”这个几何条件!
这极大地简化了问题!李航老师在书中直接使用了这个正交条件,但这是背后的推导。
2. 构造新的拉格朗日函数
现在我们的优化问题是:
我们有两个约束,所以需要两个拉格朗日乘子, 和 。
3. 对 求导并令其为0
**4. 消去乘子
这个方程里有我们不想要的 。如何消掉它?我们可以利用向量的正交性。 用 左乘上式两端:
现在我们来分析这一长串式子的每一项:
- : 根据我们的约束条件,这一项为 。
- : 根据我们推导出的简化约束,,所以这一项也为 。
- : 因为 是单位向量,所以 。
代入回去,我们得到:
这真是一个漂亮的结果!这意味着第二个拉格朗日乘子 必须是0。
现在把 代回到求导后的方程 中,得到:
5. 看看结果
这和我们对第一主成分的推导结果形式完全一样!它表明, 也必须是 的一个特征向量。
但是是哪个呢?我们的目标是最大化方差 。由于我们已经用掉了最大的特征值 给了第一主成分,并且 必须与 正交,所以我们只能在剩下的特征值中选择最大的一个。
因为对称矩阵的属于不同特征值的特征向量是天然正交的,所以我们选择的 自动满足与 正交的条件。因此,我们应该选择第二大的特征值 。
所以!第二主成分 的系数向量 是协方差矩阵 的第二大特征值 所对应的单位特征向量。第二主成分的方差就是 。
第三步:推广到第 k 主成分
通过数学归纳法,我们可以将这个逻辑推广下去。 假设我们已经求出了前 个主成分,它们的系数向量是 ,对应 的前 大的特征值 。
要求第 主成分,优化问题是:
用同样的方法构造拉格朗日函数,会发现最优解 必须是 的第 大的特征值 所对应的单位特征向量。
至此,定理16.1 证毕。
推论 16.1 和主要性质
定理证明之后,剩下的性质就都是这个核心结论的自然推论了。
推论 16.1 与 矩阵形式
推论 16.1
维随机变量 的分量依次是 的第一主成分到第 主成分的充要条件是:
- , 为正交矩阵:
- 的协方差矩阵为对角矩阵:
其中, 是 的第 个特征值, 是对应的单位特征向量,。
-
(1) : 这只是把所有 个线性变换 写成了矩阵形式。
- 是一个 的矩阵,它的每一列是我们的主成分方向向量 。
- 因为所有的 都是单位向量且相互正交,所以 是一个正交矩阵。正交矩阵有一个极好的性质: (单位矩阵)。
-
(2) 的协方差矩阵是对角矩阵 我们来推导新变量向量 的协方差矩阵:
这就是新协方差矩阵的表达式。我们知道 ,其中 是一个对角线上元素为 的对角矩阵。 所以:
这完美地证明了,经过PCA变换后,新变量的协方差矩阵是一个对角矩阵,对角元就是原始协方差矩阵的特征值。这在数学上证明了新变量之间是线性无关的。
性质 (1) & (2): 总方差不变性
- 性质(1) 就是我们刚才证明的结论:。
- 性质(2)
这个性质说明,变换前后的总方差保持不变。PCA只是将总方差进行了重新分配,将它集中到了前几个主成分上。
-
证明: 利用了矩阵的迹(trace,对角线元素之和)的性质:。
-
性质(3), (4), (5): 因子负荷量 (Factor Loadings)
这部分是解释主成分的物理意义。因子负荷量 衡量的是第k个主成分 与原始的某个变量 之间的相关系数。它的绝对值越大,说明 主要由这个 解释。
- 推导式(16.20):
- 相关系数定义:
- 代入:
- (我们已证)
- (定义)
- 关键是算分子 :
- 可以表示为 ,其中 是一个标准基向量(第i个元素是1,其余是0)。
- 因为 , 两边取转置得到 .
- 所以 (其中 是向量 的第 个分量)。
- 组合起来:
因子负荷量
-
性质(4):第k个主成分与所有原始变量的相关系数的平方和,等于其方差(特征值)。这是对主成分“能量”的另一种解释。
-
证明:
因为 是单位向量,所以它的各分量平方和 。 因此,上式等于 。得证。
-
-
性质(5):某个原始变量与所有主成分的相关系数的平方和为1(假设该变量已标准化)。这说明所有主成分一起,可以完全解释原始变量的方差。
主成分的个数
这一小节的根本目的,是为我们进行主成分分析的核心目标——降维。它旨在证明:当我们决定只保留 个新变量来近似原始数据时,选择前 个主成分是保留信息(即方差)的最优策略。这个结论由 定理16.2 给出。
定理 16.2
定理 16.2
对任意正整数 , ,考虑从 维随机变量 到 维随机变量 的任意正交线性变换
其中, 是一个 矩阵,其列向量是标准正交的(即 )。变换后变量 的协方差矩阵为
则 的迹 在 时取得最大值。这里的 是由协方差矩阵 的前 个特征向量(对应前 大的特征值)构成的矩阵。
定理 16.2 的证明
我们的目标: 求解以下优化问题:
这里的 是新变量 的方差之和,代表了变换后数据所保留的总方差。
第一步:基变换——用主成分基底表示B
这是证明中最精妙的一步。我们知道,由协方差矩阵 的 个标准正交特征向量 构成的矩阵 ,是 维空间的一组标准正交基。
这意味着,该空间中的任何一个 维向量都可以由这组基线性表示。我们的矩阵 是一个 的矩阵,它的每一个列向量 () 都是一个 维向量。因此, 可以表示为:
其中, 是向量 在基向量 上的投影坐标。
将这 个列向量的表达式合并,可以得到矩阵形式,即书中的 式(16.25):
这里, 是 的基矩阵, 是一个 的系数矩阵,其元素为 。
第二步:用新系数C重写目标函数
现在我们将 代入目标函数 :
我们在 16.1.3 节已经知道,,其中 是由 的特征值构成的对角矩阵。于是上式变为:
为了求解这个迹,我们利用迹的循环性质 :
令矩阵 ,这是一个 的矩阵。其对角线元素 是 的第 行(记为 )与自身点乘的结果:。 由于 是对角矩阵, 的计算非常简单:
这就是书中的 式(16.26),我们把目标函数成功地用系数 表示了出来。
第三步:用新系数C重写约束条件
我们的原始约束是 的列向量标准正交,即 。同样代入 :
约束条件巧妙地转化为了对系数矩阵 的约束:。==这表明,矩阵 的 个列向量也是标准正交的。==
这个约束还隐含了另一个重要性质,即 式(16.28) 的由来:
-
首先,由 ,取迹可得 式(16.27):
-
其次,由于 的列是标准正交的,我们可以将这 个 维列向量看作是某个 正交矩阵 的前 列。
-
因为 是正交矩阵,所以它的行向量也是标准正交的,即每一行的模长为1。
-
的第 行只是 的第 行的前 个元素。因此, 的第 行的模长平方必然小于等于其所在母体( 的第 行)的模长平方(即1)。
这就是 式(16.28)。
第四步:求解最终的优化问题
现在,我们的问题被彻底转化为一个关于系数 的优化问题:
约束条件为:
- (对每个 )
这是一个经典的资源分配问题。我们将总量为 的“能量”()分配给 个“项目”(由 索引),每个项目的“回报率”是 。为了使总回报最大,我们自然应该将所有能量优先分配给回报率最高的项目。
由于特征值已经排序 ,最优策略是:
- 将前 个项目的能量槽加满: for
- 不给后面的项目分配任何能量: for
这个分配方案满足所有约束条件。这个条件对应 式(16.29)。
满足这个条件的最简洁的系数矩阵 是:
即一个 矩阵,其左上角是 的单位阵,其余部分是零。 此时,最优的 为:
定理16.2证毕。这证明了,要用 个维度最大化保留原始方差,就必须选择前 个主成分。
方差贡献率
在实际操作中,我们用以下指标来决定要保留的主成分个数 :
-
定义16.2 第k主成分的方差贡献率 (Variance Contribution Rate):
它表示第 个主成分保留了总方差的百分之多少。
-
k个主成分的累计方差贡献率 (Cumulative Variance Contribution Rate):
它表示前 个主成分一共保留了总方差的百分之多少。通常我们会设定一个阈值(如80%, 90%),选择使 首次超过该阈值的 作为降维后的维度。
规范化变量的总体主成分
这一节处理一个非常实际的问题:当原始数据中不同变量的单位或量级相差悬殊时,直接做PCA是不合理的。
量纲带来的影响
PCA的核心是最大化方差。如果一个变量的数值很大(例如用“克”作单位的体重),其方差会远大于数值小的变量(例如用“米”作单位的身高)。这会导致方差大的变量在主成分中占据绝对主导地位,而方差小的变量几乎被忽略,这与变量本身的实际重要性无关,仅仅是单位选择的结果。
使用变量规范化消除量纲影响
为了让每个变量在分析中具有同等地位,我们先对其进行规范化(或称标准化),如 式(16.33) 所示:
经过规范化后,新的变量 具有如下优良特性:
- 均值
- 方差
PCA作用于相关矩阵R
对规范化后的变量 做PCA,等价于对它们的协方差矩阵进行特征值分解。我们来计算这个新的协方差矩阵:
这个最终的表达式正是原始变量 和 的相关系数 的定义!
结论: 对规范化变量 进行主成分分析,等价于对原始变量的相关矩阵 R 进行主成分分析。
规范化主成分的性质
所有之前基于协方差矩阵 的性质,现在都可以平行地应用于相关矩阵 。我们只需做如下替换:, , , 。
-
性质(1): 规范化主成分的协方差矩阵 变换后的新变量 的协方差矩阵是对角矩阵,对角元素是相关矩阵 的特征值:
-
性质(2): 总方差 总方差不变,且等于矩阵的维度 :
-
性质(3): 因子负荷量 (Factor Loading) 第 个主成分 与第 个规范化原始变量 的相关系数为:
(推导:。其中 是 的第 个特征向量 的第 个分量。)
-
性质(4): 单个主成分的因子负荷量平方和 第 个主成分 与所有原始变量的相关系数的平方和等于其方差(即对应的特征值):
(因为 是单位向量,其分量平方和为1。)
-
性质(5): 单个原始变量的因子负荷量平方和 第 个原始变量 与所有主成分的相关系数的平方和等于1:
这表明,所有的主成分合在一起,可以完全解释每一个(规范化后的)原始变量的方差(方差为1)。