1. 数学基础与符号约定
在深入CRF的公式之前,我们先明确一些基础概念和符号。这将帮助我们使用统一和严谨的语言进行讨论。
-
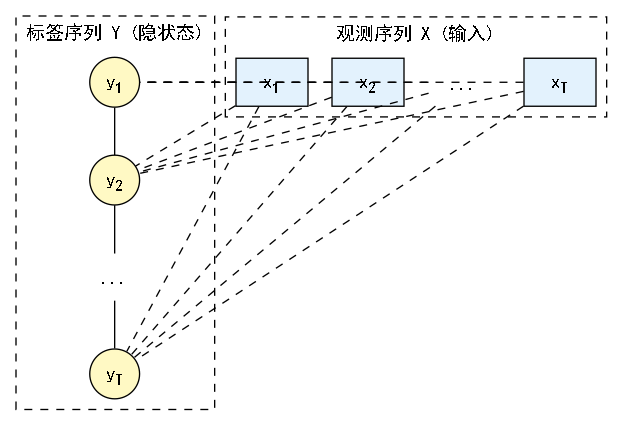
基本概念:无向图模型 (Undirected Graphical Model)
- CRF是一种无向图模型,也称为马尔可夫随机场 (Markov Random Field, MRF)。
- 它的核心思想是因子分解 (Factorization):一个复杂的概率分布可以被分解为一系列定义在图中较小“局部”上的因子 (factor) 或势函数 (potential function) 的乘积。这些局部通常是图中的团 (clique)(即图中两两之间都有边连接的顶点子集)。
- 对于线性链CRF,最关键的团就是相邻的两个标签节点,即边 。
-
符号约定
- :表示观测序列,即输入的句子中的 T 个词。
- :表示标签序列,即我们希望预测的 T 个词性。
- :表示序列中的位置,从 1 到 T。
- :表示在位置 的势函数。它是一个非负实数,用于==衡量在给定整个观测序列 的情况下,位置 的标签为 且位置 的标签为 这件事的“可能性”或“兼容性”有多高==。
2. 线性链CRF的严格定义
我们以最常见的线性链条件随机场 (Linear-chain CRF) 为例。它的图结构如下:
y1 ------ y2 ------ y3 ------ ... ------ yT
这里的 是我们想预测的标签。CRF的核心在于,它假设条件概率 的结构与这个图结构一致。根据无向图模型的因子分解理论,这个条件概率可以写成一系列定义在相邻标签对上的势函数的乘积,然后进行全局归一化。
线性链CRF的条件概率定义如下:
让我们来逐一拆解这个公式的每个部分:
-
:非归一化概率
- 这部分是模型的核心。它计算了特定标签序列 的“总分数”。
- 这个分数是通过将序列中每一个相邻位置 的“兼容性分数”(即势函数 的值)连乘得到的。
- 关键点:注意每个势函数 的输入都包含了整个观测序列 !这正是CRF能够利用全局特征的根本原因。
-
:归一化因子 (Normalization Factor)
- 也被称为配分函数 (Partition Function)。
- 它的作用是确保 是一个合法的概率分布,即对于给定的 ,所有可能的标签序列 的概率之和为1。
- 其定义为:
- 深刻理解 :这个公式的含义是,我们必须遍历所有可能的标签序列(比如一个长度为10的句子,每个词有3种词性,就有 种序列),计算出每一种序列的“总分数”,然后把它们全部加起来,得到 。
- 这使得 的计算通常非常昂贵,暴力计算是不可行的。这也正是后续我们要介绍的前向-后向算法要解决的核心问题。
3. 核心要素:特征函数 (Feature Functions)
现在,我们面临一个核心问题:势函数 到底是什么?它如何利用观测序列 的信息?答案是通过特征函数 (Feature Functions) 和它们的权重 (Weights)。
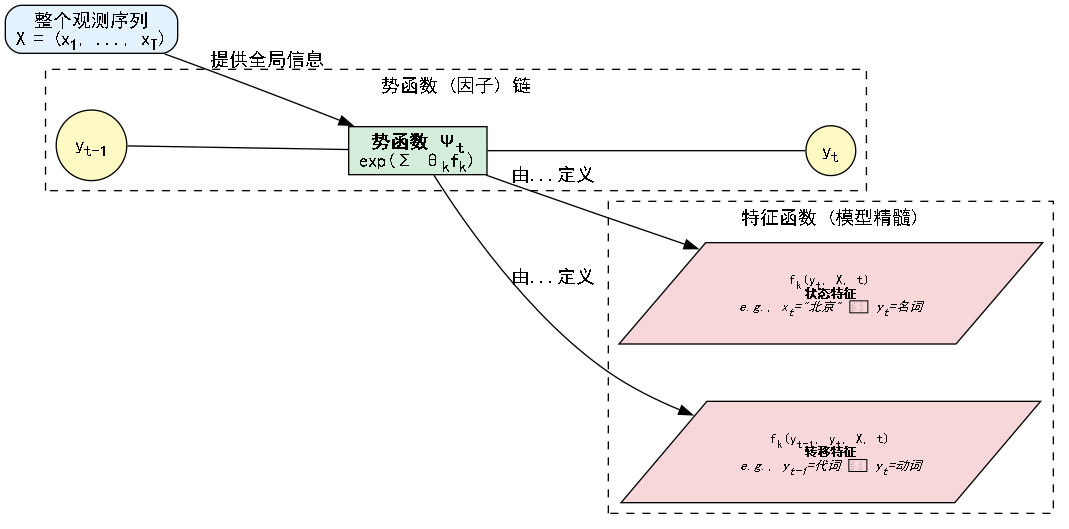
我们将势函数参数化为指数形式,这保证了其值非负,并且在数学上处理起来非常方便(属于指数族分布):
让我们再次拆解这个公式:
-
:第 个特征函数
- 这是CRF的精髓,也是模型效果好坏的关键。它由我们(模型设计者)来定义。
- 它是一个实值函数(通常取值为0或1),用于从输入数据中提取某种我们认为有用的“模式”或“证据”。
- 它的输入是:前一个标签 ,当前标签 ,整个观测序列 ,以及当前位置 。
- 它的输出代表了在当前位置 ,当标签为 时,某个特定模式是否被激活。
-
:第 个特征函数的权重
- 这是模型需要从训练数据中学习的参数。
- 每个特征函数 都对应一个权重 。
- 权重的直观含义是:
- 且较大:表示特征 是一个非常强的正面证据。当 被激活时(值为1),它会大大增加其对应标签组合的概率。
- 且较小:表示特征 是一个非常强的负面证据。当 被激活时,它会大大降低其对应标签组合的概率。
- :表示特征 几乎没有用,模型在决策时不会考虑它。
特征函数的设计示例
特征函数通常分为两类:
-
状态特征 (State Feature):只与当前标签 有关。在形式上,它们是 ,可以看作是 中不依赖于 的特例。
-
例1 (词本身): , 如果 且 ,否则为 0。 如果模型学到 是一个很大的正数,意味着“北京”这个词极有可能是名词。
-
例2 (词的形态): , 如果 且 以 “ing” 结尾,否则为 0。 如果 为正,模型就学会了 “ing” 词缀与动词有关。
-
例3 (上下文信息): , 如果 且 ,否则为 0。 如果 为正,模型就学会了冠词 “the” 后面很可能跟名词。
-
-
转移特征 (Transition Feature):与相邻标签 和 都有关。它捕捉了标签之间的依赖关系,类似于HMM中的转移概率。
- 例4 (标签转移): , 如果 且 ,否则为 0。 如果 为正,模型就学会了“代词-动词”是一个常见的标签组合。
总结一下:CRF的最终得分是所有被激活的特征函数的权重之和,再取指数。这个设计赋予了CRF巨大的灵活性和强大的建模能力。
4. CRF的简化与矩阵形式
为了方便后续的算法推导,我们通常会将CRF的定义式进行一些形式上的变换。
简化形式
将势函数的指数形式代入CRF的原始定义,我们可以利用 的性质,将连乘的指数项合并为指数的连加项:
这个形式在推导学习算法(求导)时特别有用。
矩阵形式
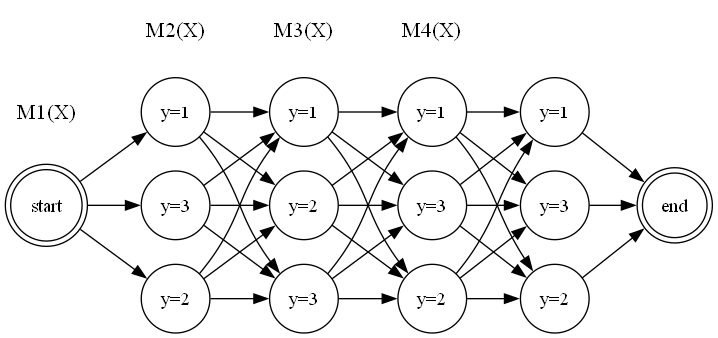
我们可以为序列中的每个位置 (从1到T) 定义一个 的转移矩阵 ,其中 是所有可能标签的数量(例如,词性有M种)。
矩阵 的第 个元素定义为:
这个元素的含义是:在给定观测 的条件下,从上一个位置的标签 转移到当前位置的标签 的非归一化分数。
有了这些矩阵,一个特定标签序列 的非归一化概率就可以表示为一系列矩阵元素的连乘:
(注:这里需要定义一个虚拟的起始状态 )
而归一化因子 ,即所有路径的非归一化概率之和,就可以通过矩阵连乘来计算:
这个矩阵视角将看似复杂的全局求和问题,转化为了一个结构化的、可以通过动态规划高效求解的矩阵运算问题。这为我们之后要介绍的算法奠定了坚实的基础。
总结
在本文中,我们:
- 严格定义了线性链CRF的条件概率公式,并理解了全局归一化因子 的核心地位。
- 深入剖析了CRF的灵魂——特征函数,理解了它是如何连接输入观测和输出标签的。
- 掌握了CRF的参数化方式,即通过学习特征权重 来构建模型。
- 引入了CRF的矩阵形式,为后续高效的推断和学习算法做好了准备。
现在,我们已经完全理解了CRF模型本身。在条件随机场(CRF)(三):三大核心问题之解码与概率计算 中,我们将学习如何在给定模型参数后,用它来解决实际问题。