1. 概述
在许多实际场景中,我们观察到的数据可能并非来自一个单一的概率分布,而是由多个不同的、潜在的子群体生成的。例如:
- 身高数据:一个班级里,男生的身高可能服从一个正态分布,女生的身高服从另一个不同的正态分布。如果我们只观测到身高数据,而不知道性别,那么整个班级的身高分布看起来就像是两个正态分布的叠加。
- 客户行为:一个电商平台的客户购买行为可能由不同的消费群体(如“精打细算型”、“高消费型”、“冲动消费型”)生成,每个群体的购买金额、频率等特征可能服从不同的分布。
高斯混合模型(GMM) 正是为了应对这类问题而设计的。它假设观测数据是由 个不同的高斯分量(Gaussian Components) 混合生成的,每个高斯分量代表一个潜在的子群体,并拥有自己的均值和方差(或协方差矩阵)。每个观测数据点都“属于”其中一个高斯分量,但我们并不知道它具体属于哪个分量,这正是GMM中的隐变量 。
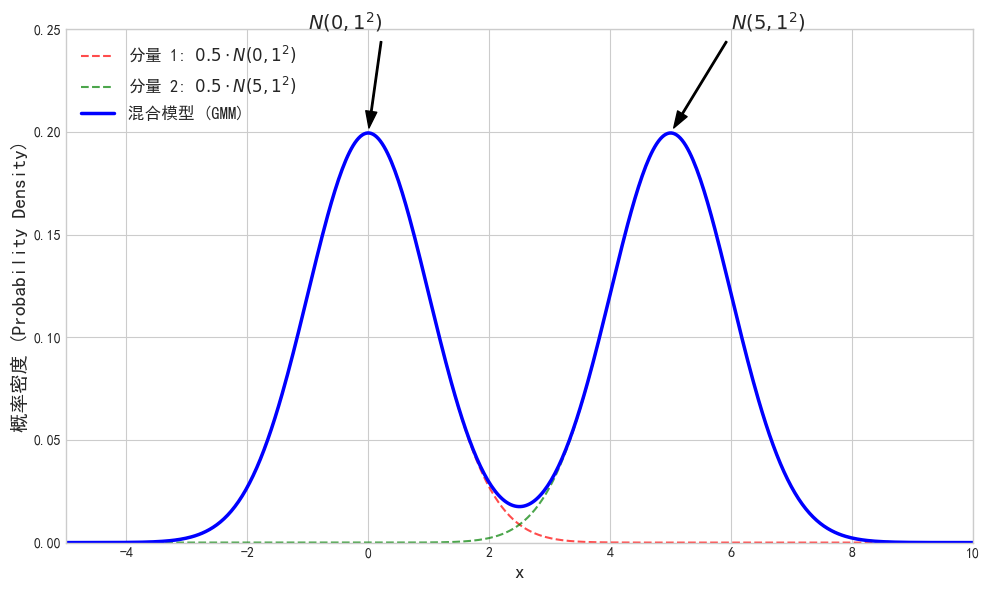
1.1 GMM的理解
想象我们在绘制数据点的直方图,发现它不是一个漂亮的钟形曲线,而是有多个“驼峰”(多峰分布),就像上面图片中展示的那样。这暗示着数据可能来自多个不同的“源”。
GMM的工作原理就是:
- 假设存在多个“源”:这些“源”就是不同的高斯分布(每个分布对应一个钟形曲线)。
- 每个源都有一个“权重”:表示数据来自这个源的可能性有多大(即混合系数)。
- 最终分布是这些源的加权叠加:通过调整每个高斯的中心(均值)、宽度(方差)以及它们的权重,GMM试图最好地拟合观测数据的多峰形状。
2. 高斯混合模型的数学定义
2.1 模型构成
一个高斯混合模型由 个高斯分量组成。每个分量 都有:
- 混合系数(Mixture Coefficient):,表示数据点来自第 个分量的概率。
- 约束条件: 且 。
- 均值(Mean):,表示第 个高斯分量的中心。
- 方差(Variance):(在一维情况下)或协方差矩阵(Covariance Matrix) (在多维情况下),表示第 个高斯分量的“宽度”或“形状”。
GMM的参数集合为 (对于多维数据, 替换为 )。
2.2 观测数据与隐变量
- 观测数据 :我们实际收集到的数据点 。每个 是一个标量(一维)或向量(多维)。
- 隐变量 :对于每个观测数据点 ,我们并不知道它具体是由哪个高斯分量生成的。这个“来源”就是隐变量。
- 我们引入一个隐变量 ,它是一个 维的独热(one-hot)向量。如果 是由第 个高斯分量生成的,那么 的第 个分量为1,其余为0。
- 例如,对于 的情况, 可以是 或 。
- 我们也可以用一个指示变量 来表示 的第 个分量:
- 如果 来自第 个分量。
- 否则。
- 显然,对于每个 ,。
2.3 高斯混合模型的概率密度函数(PMF/PDF)
对于一个观测数据点 ,其概率密度函数(PDF)是所有 个高斯分量的加权和:
其中 是第 个高斯分量的概率密度函数 。
-
高斯分布(正态分布)的PDF: 对于一维随机变量 ,均值为 ,方差为 ,其概率密度函数为:
所以,GMM的概率密度函数为:
3. GMM的概率分布推导
为了应用EM算法,我们需要推导出完整数据的联合概率分布 。
3.1 单个完整数据点 的联合概率
对于单个观测数据点 和其对应的隐变量 (指示 来自哪个分量 ),其联合概率分布可以写为:
- :这是隐变量 的先验概率,即选择第 个分量的概率。如果 的第 个分量为1(表示 来自分量 ),则 。
- :在已知 来自第 个分量的情况下, 的概率密度。这就是第 个高斯分量的PDF:。
将这两个部分结合,使用指示变量 来表示 的第 个分量为1:
- 由于对于每个 ,只有一个 是1,其余为0。所以这个乘积中只有一项是非1的,即对应于 实际来源的那个分量 的 。 例如,如果 来自第1个分量,那么 , 。则 。
3.2 完整数据集 的联合概率分布
假设我们有 个独立同分布的观测数据点,那么整个完整数据集 和 的联合概率分布就是所有单个数据点联合概率的乘积:
这个公式表示了在给定参数 的情况下,观测到所有 和所有 的概率。
3.3 完整数据对数似然函数
为了方便求导和最大化,我们通常使用对数似然函数。对上述完整数据的联合概率取对数:
这个完整数据对数似然函数可以进一步简化:
-
交换求和顺序:
对于每个 , 是常数,可以提到外面。而 正好是第 个分量所包含的样本总数。我们记 。 所以,第一项变为 。
最终,完整数据对数似然函数 为:
4. GMM的EM算法实现
现在,我们有了完整数据对数似然的表达式,就可以应用EM算法来估计GMM的参数 了。
步骤 0:初始化参数 随机初始化每个高斯分量的参数:
- 混合系数:,确保 。
- 均值:。
- 方差:。
步骤 1:E步
核心任务:计算隐变量 的后验概率,即每个观测数据点 属于第 个高斯分量的概率。这个概率通常被称为责任,记作 (或 或 )。
根据贝叶斯公式:
- 分子: 表示在当前参数下,数据点 由第 个高斯分量生成的联合概率密度。
- 分母: 表示在当前参数下,数据点 被观测到的总概率密度(对所有可能的分量求和)。
是一个介于0和1之间的值,表示我们有多大的信心认为数据点 是由第 个高斯分量生成的。对于每个数据点 ,所有分量的责任之和为1:。 这些责任值 相当于三硬币模型中的 (或 ),它们是我们在M步中用于加权估计参数的“期望的隐变量”。
构建Q函数: E步的最终目标是构建Q函数 。 我们将完整数据对数似然函数 中的隐变量指示变量 替换为其期望(即责任 ):
其中 ,表示第 个分量在当前轮的有效样本数(所有数据点对第 个分量的责任之和)。
步骤 2:M步(Maximization Step)
核心任务:最大化Q函数 关于新的参数 。
2.1 估计混合系数 我们最大化Q函数中包含 的项,同时考虑约束 。我们可以通过引入拉格朗日乘子(Lagrange Multiplier) 来解决。
我们需要最大化 。
对 求偏导并令其为0:
将所有 相加并利用 :
我们知道 (所有数据点对所有分量的责任之和等于总样本数)。 所以,。 将 代回 的表达式:
新的混合系数 等于第 个分量的有效样本数占总样本数的比例。这符合混合概率的直观理解。
2.2 估计均值 我们最大化Q函数中包含 的项:。 只关注第 个分量和 :
为了最大化,我们只需要最小化 。 对 求偏导并令其为0:
所以, 的更新公式为:
新的均值 是所有数据点的加权平均,权重就是它们对第 个分量的责任 。这符合加权平均值的定义。
2.3 估计方差 同理,我们最大化Q函数中包含 的项。 对 求偏导并令其为0(或者对 求导,然后平方):
所以, 的更新公式为:
新的方差 是所有数据点到新均值 的加权平方差的平均值,权重同样是它们对第 个分量的责任 。
步骤 3:重复迭代 将新的参数估计 作为下一轮的初始值,然后重复E步和M步,直到参数收敛(例如,当参数变化量小于某个阈值时停止,或者对数似然函数的增长小于某个阈值)。