从集成方法到AdaBoost
1. 为什么要“集成”?
在机器学习中,我们通常训练一个模型来完成分类或回归任务。但一个模型的性能往往有其局限性,比如它可能在某些数据上表现良好,但在另一些数据上则不然。这就好比一个人在做决策,即使他很聪明,也难免会有犯错的时候。
那么,有没有一种方法能够结合多个模型的智慧,从而达到比单一模型更优秀的性能呢?答案就是集成学习(Ensemble Learning)。
集成学习的核心思想是:“三个臭皮匠,顶个诸葛亮”。通过构建并结合多个学习器(也称为“基学习器”或“弱学习器”),我们可以得到一个更强大、更鲁棒的“强学习器”。这种“集体智慧”能够有效地降低模型的方差(减少过拟合风险)和偏差(提高模型准确性)。
2. 集成学习的两种主要策略:Bagging与Boosting
集成学习主要分为两大类:Bagging 和 Boosting。
2.1 Bagging(并行式集成)
- 直观理解:Bagging(例如随机森林)就好比召集了一群独立思考的专家,他们各自基于不同的训练样本子集(通过自助采样法得到)独立学习,然后将他们的预测结果进行简单组合(如投票或平均)。这些专家之间没有交流,也不互相纠正错误。
- 核心特点:并行化、降低方差。
2.2 Boosting(串行式集成)
- 直观理解:Boosting就好比一个循序渐进、不断纠错的学习过程。它不是训练一批独立的专家,而是训练一系列的专家,每个专家都在前一个专家犯错的地方重点学习。这就像一个学生在反复做题,每次都会对上次做错的题目进行反思和加倍练习。
- 第一个专家(基学习器)先学习,可能会犯一些错误。
- 第二个专家在第一个专家犯错的数据上加倍关注,努力纠正这些错误。
- 第三个专家继续纠正前两个专家仍然无法解决的问题。
- 最终,所有的专家(基学习器)被加权组合起来,形成一个更强大的决策系统。那些表现更好的专家在最终决策中拥有更大的发言权。
- 核心特点:串行化、关注错误样本、降低偏差。
Boosting方法的核心是 “迭代” 和 “加权”:
- 迭代:每一轮训练都基于前一轮的结果进行。
- 加权:
- 对训练样本进行加权:那些被前一轮弱学习器错误分类的样本,在下一轮中会被赋予更高的权重,从而得到更多的关注。
- 对弱学习器进行加权:表现越好的弱学习器,在最终的集成模型中被赋予的权重越大。
我们将要学习的 AdaBoost(Adaptive Boosting) 就是Boosting策略的经典代表。
3. AdaBoost算法:提升方法的经典代表
3.1 直观理解AdaBoost的核心思想
AdaBoost,全称“Adaptive Boosting”(自适应提升),顾名思义,它能根据训练过程中学习器的表现进行自我调整。
想象正在教一个孩子识别动物。
- 第一步:我们给他看一些动物图片,他可能会很快学会识别猫和狗,但可能经常把狐狸和狼搞混。
- 第二步:我们发现他在狐狸和狼的图片上总是出错,于是我们会特别多地给他看这两种动物的图片,并详细讲解它们的区别。
- 第三步:如果他仍然分不清某些特定品种的狗,我们会继续加强这方面的训练。
AdaBoost的工作原理与之类似:
- 它首先给每个训练样本相同的“重要性”(权重)。
- 训练一个“弱分类器”(比如一个简单的决策树桩,即只基于一个特征进行分类的树)。
- 检查这个弱分类器在哪里犯了错误。
- 重点来了:对于那些被错误分类的样本,AdaBoost会提高它们的权重,使得下一个弱分类器在训练时,会更关注这些之前被“忽略”或“分错”的样本。
- 同时,对于当前这个表现较好的弱分类器,AdaBoost会赋予它一个更高的投票权重。
- 这个过程循环往复,直到达到预设的迭代次数或满足某些停止条件。
- 最终,所有的弱分类器根据它们的权重进行加权投票,得到最终的强分类器。
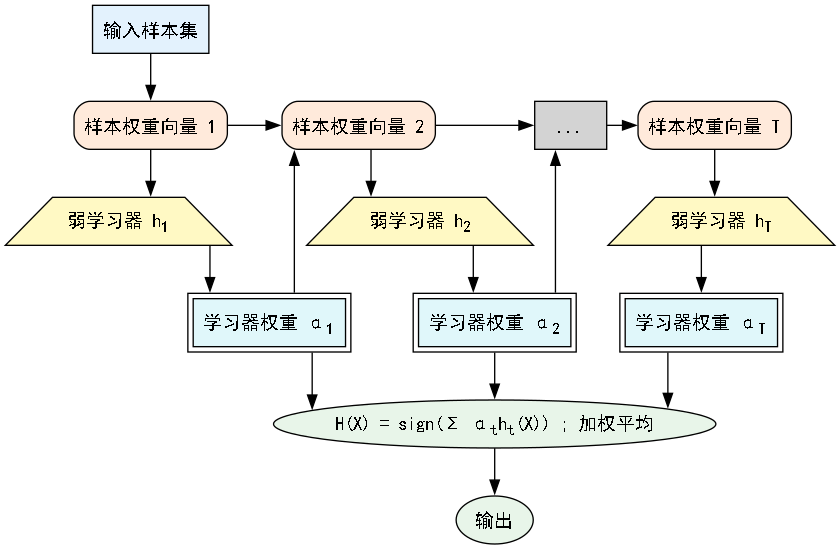
3.2 AdaBoost的基本流程概述
- 初始化:给所有训练样本赋予相同的初始权重。
- 循环迭代(M轮):
- 在当前样本权重分布下,训练一个弱分类器。
- 计算这个弱分类器在训练集上的分类误差率。
- 根据误差率,计算这个弱分类器的重要性(权重)。误差率越小,权重越大。
- 更新训练样本的权重:提高被当前弱分类器错误分类的样本的权重,降低被正确分类的样本的权重。这样,下一轮的弱分类器将更关注那些难以分类的样本。
- 组合:将所有M个弱分类器进行加权组合,形成最终的强分类器。
4. AdaBoost算法的数学基础与符号定义
为了更严谨地理解AdaBoost,我们首先定义一些在算法中将使用的数学符号:
- 训练数据集:
- : 样本总数。
- : 第 个样本的特征向量(输入)。
- : 第 个样本的标签(输出),在二分类问题中,通常取值为 。
- 迭代次数:
- 算法总共训练 个弱分类器。
- 第 轮迭代 (其中 ):
- 样本权重分布:
- : 第 轮中第 个样本的权重。初始时,所有 。
- 所有权重的和为1,即 。
- 弱分类器:
- 在第 轮训练出的基分类器,它接收一个样本 作为输入,输出其预测标签 。
- 弱分类器的误差率:
- 表示 在当前加权训练集上的分类误差。
- 弱分类器的权重:
- 表示 在最终强分类器中的重要性。
- 样本权重分布:
- 最终强分类器:
- 由所有 个弱分类器加权组合而成。
数学工具:指示函数 指示函数是一个非常有用的工具,它用于判断某个条件是否成立。
-
当条件成立时,指示函数输出1。
-
当条件不成立时,指示函数输出0。 其定义如下:
例如,如果 表示第 个样本被 错误分类,那么 在样本被分错时为1,分对时为0。
5. AdaBoost算法的详细机制与推导
我们将详细拆解AdaBoost算法的每一步,并对核心公式进行推导。
5.1 训练样本权重的初始化
在第一轮训练开始时,所有训练样本被认为是同等重要的。因此,我们为每个样本赋予相同的初始权重。
- 这里 是训练样本的总数。这意味着每个样本最初的重要性都是 。
5.2 弱分类器的训练与误差率计算
在第 轮迭代中,AdaBoost会基于当前的样本权重分布 ,训练出一个弱分类器 。这个弱分类器通常是一个简单的模型,例如一个决策树桩。
接着,计算这个弱分类器 在当前加权训练集上的分类误差率 。
- 解释:
- 表示概率,在这里等同于加权平均。
- 是指示函数。如果第 个样本被 错误分类,则此项为1;否则为0。
- 所以, 就是所有被错误分类的样本的权重之和。这个值衡量了当前弱分类器在加权样本集上的表现。
5.3 弱分类器权重的计算
一旦我们得到了弱分类器 的误差率 ,我们就可以计算它在最终强分类器中的权重 。
- 解释:
- 表示自然对数(以 为底)。
- 这个公式设计得非常巧妙,其直观意义是:
- 如果 (即弱分类器比随机猜测好),那么 ,,所以 ,因此 。分类器性能越好( 越小), 越大,从而 越大。这意味着表现好的弱分类器在最终决策中拥有更大的话语权。
- 如果 (即弱分类器比随机猜测还差),那么 ,,所以 ,因此 。这意味着一个很差的分类器可以被赋予负权重,从而“反向投票”,起到纠正作用。但实际应用中,如果 太大,通常会直接丢弃这个弱分类器或停止训练。
5.4 训练样本权重的更新
这是AdaBoost最核心也是最精妙的部分。它负责调整样本的权重,使得在下一轮训练中,那些被当前弱分类器 错误分类的样本能得到更多的关注。
新的样本权重 是根据旧权重 和当前弱分类器 的表现来计算的。 对于每个样本 ,其新的权重 计算如下:
其中 是一个归一化因子,它的作用是确保所有样本的新权重之和仍然为1。
-
解释 :在更新权重后,新的权重之和可能不再是1。 就用来将所有新权重缩放到总和为1的比例,使其成为一个有效的概率分布。
-
详细推导并解释 项: 这个指数项是理解权重更新的关键。我们知道 是真实标签 (), 是预测标签 ()。
- 情况一:样本被正确分类 () 此时 或者 。 指数项变为 。 由于 (因为弱分类器通常要比随机猜测好),所以 。 这意味着:被正确分类的样本,其权重会乘以一个小于1的因子,从而权重减小。
- 情况二:样本被错误分类 () 此时 或者 。 指数项变为 。 由于 ,所以 。 这意味着:被错误分类的样本,其权重会乘以一个大于1的因子,从而权重增大。
通过这种方式,AdaBoost巧妙地实现了“关注错误样本”的目的:分错的样本权重增加,在下一轮训练中会得到弱分类器更多的关注;分对的样本权重减小,重要性降低。
5.5 最终分类器的组合
经过 轮迭代后,我们得到了 个弱分类器 以及它们对应的权重 。 最终的强分类器 采用加权多数表决的方式结合这些弱分类器:
- 解释:
- :计算每个样本 被所有弱分类器加权预测的总和。
- :符号函数。如果括号内的和大于0,则输出 ;如果小于0,则输出 。这相当于根据加权投票结果决定最终的类别。
6. AdaBoost算法的数值计算示例
现在,我们将使用一个简化的二分类数据集来演示AdaBoost的详细计算过程。
训练数据集:10个样本,特征 ,标签 。
| 序号 | ||
|---|---|---|
| 1 | 0 | 1 |
| 2 | 1 | 1 |
| 3 | 2 | 1 |
| 4 | 3 | -1 |
| 5 | 4 | -1 |
| 6 | 5 | -1 |
| 7 | 6 | 1 |
| 8 | 7 | 1 |
| 9 | 8 | 1 |
| 10 | 9 | -1 |
目标:演示前两轮迭代的详细计算。
6.1 第一轮迭代 ()
步骤 1:初始化样本权重 总样本数 ,所以每个样本的初始权重是 。
步骤 2:训练弱分类器 并计算误差率 我们寻找一个最优的决策树桩(即一个阈值 ),使得当 时分类为 ,当 时分类为 ;或者当 时分类为 ,当 时分类为 。
通过对数据进行观察和尝试,我们会发现当阈值 时,弱分类器 表现较好:
让我们看看 的分类结果:
| 序号 | 错误样本 | |||||
|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 1 | 0 | 0.1 | |
| 2 | 1 | 1 | 1 | 0 | 0.1 | |
| 3 | 2 | 1 | 1 | 0 | 0.1 | |
| 4 | 3 | -1 | -1 | 0 | 0.1 | |
| 5 | 4 | -1 | -1 | 0 | 0.1 | |
| 6 | 5 | -1 | -1 | 0 | 0.1 | |
| 7 | 6 | 1 | -1 | 1 | 0.1 | Yes |
| 8 | 7 | 1 | -1 | 1 | 0.1 | Yes |
| 9 | 8 | 1 | -1 | 1 | 0.1 | Yes |
| 10 | 9 | -1 | -1 | 0 | 0.1 |
计算 的误差率 : 错误分类的样本是序号7、8、9。它们的原始权重都是0.1。
- 解释: 错了3个样本,且这3个样本的初始权重之和为0.3。
步骤 3:计算弱分类器 的权重
- 解释:由于误差率 ,所以 是一个正数,表示 是一个有效的弱分类器,在最终模型中有一定的发言权。
步骤 4:更新训练样本的权重 我们需要计算每个样本的 。 首先,计算指数项 :
- 对于正确分类的样本 ():
- 对于错误分类的样本 ():
| 序号 | ||||
|---|---|---|---|---|
| 1 | 0.1 | 1 | 0.655 | |
| 2 | 0.1 | 1 | 0.655 | |
| 3 | 0.1 | 1 | 0.655 | |
| 4 | 0.1 | 1 | 0.655 | |
| 5 | 0.1 | 1 | 0.655 | |
| 6 | 0.1 | 1 | 0.655 | |
| 7 | 0.1 | -1 | 1.527 | |
| 8 | 0.1 | -1 | 1.527 | |
| 9 | 0.1 | -1 | 1.527 | |
| 10 | 0.1 | 1 | 0.655 | |
| 总和 |
我们采用近似值,将 用于后续计算。
现在计算 中每个样本的权重 :
- 对于正确分类的样本 (1,2,3,4,5,6,10):
- 对于错误分类的样本 (7,8,9):
所以,更新后的样本权重 为:
- 观察:之前被 错误分类的样本 (序号7, 8, 9) 的权重明显增大(从0.1变为0.1622),而被正确分类的样本的权重则减小(从0.1变为0.0696)。
6.2 第二轮迭代 ()
步骤 1:在 权重分布下,训练弱分类器 并计算误差率 现在,我们要在 这个新的样本权重分布上,寻找新的最佳弱分类器 。 通过观察和尝试,当**阈值 **时,弱分类器 表现较好:
让我们看看 的分类结果:
| 序号 | 错误样本 | |||||
|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 1 | 0 | 0.0696 | |
| 2 | 1 | 1 | 1 | 0 | 0.0696 | |
| 3 | 2 | 1 | 1 | 0 | 0.0696 | |
| 4 | 3 | -1 | 1 | 1 | 0.0696 | Yes |
| 5 | 4 | -1 | 1 | 1 | 0.0696 | Yes |
| 6 | 5 | -1 | 1 | 1 | 0.0696 | Yes |
| 7 | 6 | 1 | 1 | 0 | 0.1622 | |
| 8 | 7 | 1 | 1 | 0 | 0.1622 | |
| 9 | 8 | 1 | 1 | 0 | 0.1622 | |
| 10 | 9 | -1 | -1 | 0 | 0.0696 |
计算 的误差率 : 错误分类的样本是序号4、5、6。它们的权重都是0.0696。
- 解释:尽管 也错了3个样本,但由于这些样本在 中的权重较低,因此总的加权误差率 比 小。
步骤 2:计算弱分类器 的权重
- 解释:由于 ,所以 ,这说明 在当前的样本分布下表现更好,因此在最终模型中权重更大。
步骤 3:更新训练样本的权重 (为保持示例简洁,此处不再详述 的计算,但过程与 的计算完全相同。)
- 对于正确分类的样本 (): 权重将乘以
- 对于错误分类的样本 (): 权重将乘以 例如,序号4, 5, 6的样本的权重会从 增加到 (再归一化)。而序号7, 8, 9的样本权重会从 减小到 (再归一化)。
6.3 最终强分类器的组合
假设我们只训练了两轮,那么最终的强分类器 为:
让我们随机取一个样本 ,看看它的预测结果:
- (因为 )
- (因为 ) 将它们代入 :
样本 的真实标签是 ,最终强分类器 也预测为 。 有趣的是,在第一轮中 将 分类错误(预测为-1),但在第二轮中 将其分类正确(预测为+1),并且 的权重更高,最终的强分类器能够正确地纠正这个错误! 这正是Boosting的威力所在。
让我们再看一个例子 :
- (因为 )
- (因为 ) 将它们代入 :
样本 的真实标签是 ,最终强分类器 预测为 。这个样本仍然被分错了!这说明两轮迭代可能还不够,或者弱分类器不够理想。通过更多的迭代,AdaBoost会继续调整权重,直到找到一个更好的组合。
7. Python代码演示 (使用NumPy)
这里提供一个简化版的AdaBoost实现,以帮助我们将数学公式与代码对应起来。为了避免过度复杂化,弱分类器将直接使用NumPy实现一个简单的阈值分类器。
import numpy as np
def train_weak_classifier(X, y, sample_weights):
"""
训练一个简单的弱分类器(决策树桩),并返回其预测和误差。
这里简化为寻找一个最佳阈值来分割数据。
"""
best_error = float('inf')
best_threshold = None
best_prediction = None
# 尝试所有可能的分割点 (这里简化为样本的x值)
unique_X = np.sort(np.unique(X))
for threshold in unique_X:
# 尝试两种分类方向:x < threshold -> +1, x >= threshold -> -1
pred1 = np.where(X < threshold, 1, -1)
error1 = np.sum(sample_weights[y != pred1])
# 尝试另一种分类方向:x < threshold -> -1, x >= threshold -> +1
pred2 = np.where(X < threshold, -1, 1)
error2 = np.sum(sample_weights[y != pred2])
if error1 < best_error:
best_error = error1
best_threshold = threshold
best_prediction = pred1
best_direction = (1, -1) # Represents if x < T -> +1, x >= T -> -1
if error2 < best_error:
best_error = error2
best_threshold = threshold
best_prediction = pred2
best_direction = (-1, 1) # Represents if x < T -> -1, x >= T -> +1
# 返回最佳弱分类器(阈值和方向),其预测结果,以及误差
return best_threshold, best_direction, best_prediction, best_error
def adaboost_train(X, y, M=2): # M为迭代次数
N = len(X)
# 步骤 1:初始化样本权重 D1
sample_weights = np.full(N, 1/N)
weak_classifiers = [] # 存储训练好的弱分类器 G_m
alphas = [] # 存储弱分类器对应的权重 alpha_m
for m in range(M): # 迭代M轮
print(f"\n--- 第 {m+1} 轮迭代 ---")
# 步骤 2a:训练弱分类器 G_m(x)
threshold, direction, G_m_pred, e_m = train_weak_classifier(X, y, sample_weights)
# 打印当前弱分类器及其误差
print(f"弱分类器 G_{m+1}: 阈值={threshold}, 方向={direction[0]} (x < {threshold}), {direction[1]} (x >= {threshold})")
print(f"加权误差率 e_{m+1} = {e_m:.4f}")
# 检查误差是否过大 (例如,比随机猜测还差)
if e_m >= 0.5:
print(f"警告: 弱分类器误差率 {e_m:.4f} 过高,停止训练。")
break
# 步骤 3:计算弱分类器 G_m(x) 的权重 alpha_m
alpha_m = 0.5 * np.log((1 - e_m) / e_m)
print(f"弱分类器权重 alpha_{m+1} = {alpha_m:.4f}")
weak_classifiers.append({'threshold': threshold, 'direction': direction})
alphas.append(alpha_m)
# 步骤 4:更新训练样本的权重 D_{m+1}
# 找到被G_m分错的样本索引
incorrect_indices = np.where(y != G_m_pred)[0]
# 找到被G_m分对的样本索引
correct_indices = np.where(y == G_m_pred)[0]
# 错误分类样本的权重增加
sample_weights[incorrect_indices] *= np.exp(alpha_m)
# 正确分类样本的权重减小
sample_weights[correct_indices] *= np.exp(-alpha_m)
# 归一化因子 Z_m
Z_m = np.sum(sample_weights)
sample_weights /= Z_m
print(f"更新后的样本权重 D_{m+2}:")
print(np.round(sample_weights, 4))
return weak_classifiers, alphas
def adaboost_predict(X_test, weak_classifiers, alphas):
"""
使用训练好的强分类器进行预测。
"""
final_predictions = np.zeros(len(X_test))
for i, clf in enumerate(weak_classifiers):
threshold = clf['threshold']
direction = clf['direction']
alpha = alphas[i]
# 根据弱分类器定义进行预测
if direction[0] == 1: # x < threshold -> +1, x >= threshold -> -1
G_m_pred = np.where(X_test < threshold, 1, -1)
else: # x < threshold -> -1, x >= threshold -> +1
G_m_pred = np.where(X_test < threshold, -1, 1)
final_predictions += alpha * G_m_pred
return np.sign(final_predictions)
# 示例数据 (与我们提供的表格一致)
X = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = np.array([1, 1, 1, -1, -1, -1, 1, 1, 1, -1])
# 训练AdaBoost模型 (两轮)
M_iterations = 2
trained_classifiers, trained_alphas = adaboost_train(X, y, M=M_iterations)
# 步骤 5:最终强分类器的组合与预测
print("\n--- 最终强分类器的预测 ---")
predictions = adaboost_predict(X, trained_classifiers, trained_alphas)
print("真实标签:", y)
print("模型预测:", predictions)
print("分类准确率:", np.sum(predictions == y) / len(y))
# 检查一个具体样本,如 x=7
test_x = np.array([7])
pred_7 = adaboost_predict(test_x, trained_classifiers, trained_alphas)
print(f"样本 x=7 的预测结果: {pred_7[0]} (真实值: {y[X==7][0]})")
# 检查一个具体样本,如 x=4
test_x_4 = np.array([4])
pred_4 = adaboost_predict(test_x_4, trained_classifiers, trained_alphas)
print(f"样本 x=4 的预测结果: {pred_4[0]} (真实值: {y[X==4][0]})")
代码运行输出示例(与手动计算结果一致):
--- 第 1 轮迭代 ---
弱分类器 G_1: 阈值=3, 方向=1 (x < 3), -1 (x >= 3)
加权误差率 e_1 = 0.3000
弱分类器权重 alpha_1 = 0.4236
更新后的样本权重 D_2:
[0.0714 0.0714 0.0714 0.0714 0.0714 0.0714 0.1667 0.1667 0.1667 0.0714]
--- 第 2 轮迭代 ---
弱分类器 G_2: 阈值=9, 方向=1 (x < 9), -1 (x >= 9)
加权误差率 e_2 = 0.2143
弱分类器权重 alpha_2 = 0.6496
更新后的样本权重 D_3:
[0.0455 0.0455 0.0455 0.1667 0.1667 0.1667 0.1061 0.1061 0.1061 0.0455]
--- 最终强分类器的预测 ---
真实标签: [ 1 1 1 -1 -1 -1 1 1 1 -1]
模型预测: [ 1. 1. 1. 1. 1. 1. 1. 1. 1. -1.]
分类准确率: 0.7
样本 x=7 的预测结果: 1.0 (真实值: 1)
样本 x=4 的预测结果: 1.0 (真实值: -1)
8. 什么是PAC学习框架 (Probably Approximately Correct Learning)
8.1 我们如何衡量“学得好”?
在前面的AdaBoost介绍中,我们训练了一个分类器。但我们如何知道这个分类器学得“好不好”呢?
- 仅仅在训练集上表现好是不够的,因为模型可能过拟合。
- 我们需要模型在未见过的数据上也能表现良好,这被称为泛化能力。
PAC学习框架正是为了回答这个问题而诞生的。它提供了一个数学上严谨的定义来描述什么叫做一个“可学习”的问题,以及在什么条件下我们可以认为一个学习算法是“好”的。它将“学得好”分解为两个关键维度:
- 近似正确 (Approximately Correct):我们希望学到的模型在未来的数据上,其预测错误率很低。
- 可能 (Probably):我们希望学到的模型以很高的概率是近似正确的。因为我们是从有限的样本中学习,总存在小概率事件导致学得不好。
简而言之,PAC学习框架就是说:“一个问题是可学习的,如果存在一个算法,它能够以很高的概率(Probably),学到一个近似正确(Approximately Correct)的模型。”
8.2 PAC学习框架的核心思想
让我们想象一个 “神箭手” 正在练习射箭。
- Correct (正确):神箭手的目标是射中靶心。在机器学习中,这对应着找到一个完美的模型,它对所有可能的输入都能做出100%正确的预测。在真实世界中,这样的完美模型往往是不存在的。
- Approximately (近似地):既然不能100%正确,那么允许犯一点错误是不是可以接受呢?“近似地正确”意味着我们容忍神箭手稍微偏离靶心一点点,只要箭落在靶心周围的某个小圈内,我们就认为他是“命中”了。在机器学习中,这对应着我们允许模型犯小于某个小错误率 的错误。
- Probably (以很高的概率):即使神箭手能力再强,他也不能保证每一箭都落在那个“近似正确”的小圈内。他可能会偶尔失手,射到靶子外面。但是,如果他绝大多数时候(以很高的概率) 都能将箭射在那个小圈内,我们就认为他是一个可靠的神箭手。在机器学习中,这对应着我们希望学习算法能够以不低于某个高概率 的把握,学到一个错误率小于 的模型。这里的 是一个很小的概率值,代表了我们“学砸了”的风险。
所以,PAC学习框架就是:我们希望找到一个算法,它能够以很高的概率(比如99%的概率),学到一个近似正确的模型(比如在测试数据上的错误率不超过5%)。
8.3 PAC学习框架的相关数学符号与概念
为了严谨地定义PAC学习,我们需要引入一些数学符号和概念。PAC学习通常用于概念学习或分类问题。
- 输入空间(Input Space):。所有可能的输入样本 的集合。例如,图像的像素值,文本的词向量等。
- 输出空间(Output Space):。所有可能的输出标签 的集合。在二分类中,通常是 或 。
- 概念(Concept)或目标函数(Target Function):。这是一个未知的、真实的映射关系,我们希望通过学习来近似它。可以理解为 “大自然” 或 “真相” 。我们无法直接观察到它,只能通过数据来推断。
- 概念类(Concept Class):。所有可能的目标概念 的集合。例如,所有可能的线性分类器,或者所有可能的决策树等。我们假设我们要学习的真实概念 是属于这个概念类的,即 。
- 分布(Distribution):。输入空间 上的一个概率分布。它描述了不同样本 出现的概率。我们假设训练数据和未来的测试数据都服从这个 相同但未知 的分布。
- 训练样本(Training Samples):。这些样本是从分布 中独立同分布地抽取,并且标签 是由真实概念 生成的。 是样本数量。我们通常表示 ,表示 是从 中抽取 个样本。
- 假设空间(Hypothesis Space):。学习算法能够输出的所有可能的模型的集合。通常, 是一个预设好的模型家族,例如所有线性函数、所有决策树等。学习算法的目标是从 中选择一个假设 来近似 。
- 学习算法(Learning Algorithm):。一个函数,它接收训练样本 作为输入,并输出一个假设 。
- 泛化误差(Generalization Error): 或 。对于一个假设 ,其在未知分布 上的真实错误率。
- 解释:这是在整个数据分布上,假设 做出错误预测的概率。这是我们最关心的误差,但由于 和 未知,我们无法直接计算它。
- 经验误差(Empirical Error):。对于一个假设 ,其在训练样本 上的错误率。
- 解释:这是我们通过训练数据可以计算的误差。学习算法的目标是找到一个经验误差小的假设。
8.4 PAC学习的正式定义与推导
PAC学习
Definition (PAC-learning): A concept class is said to be PAC-learnable if there exists an algorithm and a polynomial function such that for any and , for all distributions on and for any target concept , the following holds for any sample size :
If further runs in , then is said to be efficiently PAC-learnable. When such an algorithm exists, it is called a PAC-learning algorithm for .
让我们逐行拆解这个定义:
第一部分:核心条件 -
这是PAC定义的核心数学表达式。
- :这个表示由学习算法 基于训练样本 学习到的假设 的泛化误差。我们前面已经定义了泛化误差,它是 在未知真实数据分布 上的真实错误率。
- :这是 “近似正确” 的量化。我们希望学到的假设 的泛化误差小于或等于一个小的正数 (epsilon)。 是一个准确度参数,通常我们希望它越小越好(例如, 意味着我们希望真实错误率不超过5%)。
- :这是 “可能” 的量化。由于学习算法是基于随机抽取的训练样本 来学习的,所以学到的假设 也是一个随机变量。我们希望以至少 的概率,学到的假设 是近似正确的。(delta)是一个很小的正数,通常被称为置信度参数或失败概率。 是我们对学习结果的置信度(例如, 意味着我们有99%的信心,学到的模型是近似正确的)。
综合理解这个不等式: 对于任何给定的精确度要求 和置信度要求 ,如果一个概念类是PAC可学习的,那么存在一个学习算法 ,它通过从分布 中抽取足够多的样本 ,能够以至少 的概率,找到一个假设 ,使得这个假设在未来未知的分布 上犯的错误(即泛化误差 )不超过 。
第二部分:样本复杂度 -
这部分定义了“可学习”所需的样本数量。
- : 训练样本的数量。
- : 表示一个多项式函数。例如, 可以是 或者 等。
- 和 :我们希望 越小(越精确), 越小(越自信),那么我们需要的样本 就越多。这里要求 随 和 多项式增长,而不是指数增长。如果是指数增长,意味着即使稍微提高一点精度或置信度,都需要天文数字的样本,这在实际中是不可行的。
- :这个术语通常指目标概念 的复杂性度量,例如如果 是一个布尔函数,它的“大小”可能是表示它所需的门的数量;如果是决策树,可能是树的深度或节点数。这表示,即使目标概念本身的复杂性增加,所需的样本数也只是多项式增长。
综合理解这部分: “PAC可学习”要求所需的训练样本数量 必须是 、 和 的一个多项式函数。这保证了在实践中,我们可以通过相对较少(多项式级别)的数据量来学习一个足够好的模型。如果需要指数级的样本才能学好,那我们就认为这个概念是不可学习的(至少在计算学习理论的意义上)。
第三部分:计算效率 - “efficiently PAC-learnable”
这部分定义了“有效”或“高效”的PAC学习。
- Algorithm further runs in :
- 除了样本复杂度是多项式的,学习算法 本身的运行时间也必须是 , , 样本维度 (如果 是 维向量) 和 的一个多项式函数。
- 这里的 指的是输入 的维度,例如图像的像素数量,或者特征向量的长度。
- 这意味着我们不仅可以从有限样本中学到东西,而且这个学习过程本身是计算可行的。
综合理解: 一个概念类被称为高效PAC可学习,如果不仅存在一个PAC学习算法,而且这个算法的运行时间是多项式级别的。这是理论与实践结合的关键点,因为如果算法运行时间过长,即使理论上可学也无实际意义。
8.5 为什么PAC学习框架很重要?
PAC学习框架的重要性体现在以下几个方面:
- 提供了学习的理论基础:它回答了“在什么条件下,从数据中学习是可能的和可行的”这一根本问题。它建立了机器学习的数学理论基石。
- 量化了学习的质量:通过 和 参数,它明确了我们对学习结果的“准确度”和“置信度”要求,使得学习过程的性能可以被严格评估。
- 指明了样本量的需求:它量化了学习一个好模型所需的最小样本量(样本复杂度),这对实际应用中数据收集和模型选择有指导意义。
- 连接了理论与计算复杂性:引入了“高效”PAC可学习,将学习问题与计算复杂性理论联系起来,确保学习过程是可计算的。
- 推动了算法发展:为了证明某些概念类是PAC可学习的,研究者需要设计出满足这些条件的算法,这极大地推动了机器学习算法的发展。例如,AdaBoost的成功正是弱可学习与强可学习等价性(在PAC框架下)的最好体现。
8.6 从PAC框架到弱可学习与强可学习
“弱学习与强学习”以及Valiant和Schapire的论文,正是PAC框架下非常重要的概念:
- 弱可学习 (Weakly Learnable):如果一个概念类是PAC可学习的,但只要求 是一个常数(例如,错误率略小于0.5,比随机猜测好一点点),而不是可以任意小。换句话说,存在一个算法,它能以很高的概率学到一个“弱分类器”,这个分类器仅仅比随机猜测好那么一点点(例如,分类准确率略高于50%)。
- 强可学习 (Strongly Learnable):如果一个概念类是PAC可学习的,并且 可以是任意小的正数。也就是说,存在一个算法,它能以很高的概率学到一个“强分类器”,这个分类器可以达到任意高的精度。
Schapire的定理(1990) 证明了一个惊人的结论:弱可学习与强可学习是等价的! 这意味着,如果你能找到一个算法,仅仅能学到比随机猜测好一点点的“弱分类器”,那么你就可以通过某种方式(例如,Boosting方法,如AdaBoost)把这些弱分类器组合起来,“提升”成一个任意精确的“强分类器”。
9. AdaBoost的损失函数、系数推导与权重更新
在前面的讨论中,我们直观地理解了AdaBoost的工作原理,并通过数值例子演示了其计算过程。现在,我们将深入到算法的数学原理层面,特别是它所优化的损失函数,以及如何从中推导出弱分类器系数 和样本权重更新公式 。
9.1 AdaBoost的损失函数
AdaBoost算法被证明是在优化一个特定的损失函数——指数损失(Exponential Loss Function)。理解这一点,是理解所有系数和权重更新公式的钥匙。
直观理解指数损失: 在二分类问题中,如果真实标签是 ,模型的预测输出是 (注意,这里的 是一个实数值,而不是直接的 标签),那么指数损失的定义是:
- 为什么用指数?
- 惩罚程度:当 越小(即预测值 与真实标签 的符号越不一致,或者符号虽然一致但信心不足),损失值 越大。特别地,当 (预测错误)时,,损失值呈指数级增大,惩罚非常重。这使得模型对错误分类的样本非常敏感,会努力去纠正它们。
- 连续可导:指数函数是处处连续可导的,这使得我们可以使用梯度下降等优化方法。
损失函数的最小化目标: AdaBoost的训练目标是构建一个加性模型 ,使得在训练集上的加权指数损失最小化。
在第 轮迭代中,我们假设已经得到了前 个弱分类器的线性组合 。现在,我们要在当前样本权重分布 下,找到第 个弱分类器 及其系数 ,使得加入 后的模型 的指数损失最小化。
当前模型表示为:。
我们要最小化的目标函数是:
由于 ,我们可以拆开指数项:
在第 轮迭代中, 对于当前这一轮来说是一个常数项。我们可以将其与第 轮的样本权重 联系起来。事实上,AdaBoost的样本权重 就是前一轮优化累积的损失结果:
更精确地说,更新后的权重 ,就是为了使得 成立。
因此,在第 轮中,我们最小化的目标可以写成:
9.2 弱分类器 的选择
在每一轮中,我们首先选择一个最优的 ,使其能够最小化上述目标函数。
这意味着 就是在当前样本权重 下,训练出的加权错误率最小的那个基分类器。 这对应着我们 AdaBoost 算法步骤中的“在当前样本权重分布 下,训练一个弱分类器 ”。其加权误差率 。
9.3 弱分类器权重 的推导
一旦确定了 ,我们就需要计算其权重 。我们通过对目标函数 关于 求导并令导数等于0来找到最优的 。
目标函数可以分为两部分:
- 正确分类的样本:。
- 错误分类的样本:。
令目标函数为 。
我们知道:
- 所有正确分类样本的权重和为
- 所有错误分类样本的权重和为
所以, 可以简化为: 现在,我们对 关于 求导,并令导数等于0: 将 移到左侧, 移到右侧: 为了解出 ,两边取自然对数: 最终得到: 这解释了AdaBoost中弱分类器权重 的由来,它正是通过最小化指数损失函数得到的。
9.4 样本权重 的更新推导
样本权重的更新旨在让下一轮的弱分类器更关注被前一轮错误分类的样本。这个更新公式也直接来源于最小化指数损失。
我们知道,第 轮结束后,模型的预测可以表示为 。 为了使损失函数能够被迭代地最小化,每一轮的样本权重 应该与 成正比,并且为了保持它们是概率分布,需要进行归一化。
我们来证明 。
从定义开始:
我们将 用其前一轮的表示代替,即 :
利用指数函数的性质 :
由于 ,代入上式得到:
10. AdaBoost训练误差上界分析
AdaBoost的另一个强大之处在于其严格的训练误差上界。这意味着我们可以理论上证明,随着迭代次数的增加,训练误差会呈指数级下降。
10.1 指示函数与指数损失的关系
AdaBoost最终的分类器是 。 我们关心的是训练误差,即 。
而对于任意的 和实数 ,如果 ,那么 。 在这种情况下,我们有 。
- 证明:如果 ,那么 。而对于任何 ,我们知道 (因为预测错误时,)。
- 如果 ,则 ,此时 可能小于1,也可能大于1。但关键在于,只有当分类错误时,指示函数才为1。
因此,我们可以得出以下关键不等式:
- 解释:当最终分类器 错误分类样本 时,,此时 ,而 ,所以不等式成立。当正确分类时,,而 是一个正数,不等式也成立。 这个不等式非常重要,它将我们离散的0/1误差转换成了连续可导的指数损失。
所以,最终分类器的训练误差可以被指数损失的平均值所上界:
10.2 训练误差上界与规范化因子 的关系推导
接下来,我们证明这个上界可以表示为所有规范化因子 的连乘积。
我们知道,样本权重 的定义是:
将 用前一轮的权重表示:
代入上式并递归展开:
持续递归,直到 :
现在,我们对所有样本的 求和。我们知道 (因为 是一个概率分布)。
将与 无关的项移到求和符号外面:
因此,我们可以得到:
结合之前推导的不等式 , 我们最终得到了AdaBoost训练误差的上界:
这就是统计机器学习中定理8.1的公式(8.9)。
这个公式揭示了AdaBoost训练误差的一个非常重要的性质:最终分类器的训练误差的上界等于每一轮迭代中归一化因子 的连乘积。 由于每一轮我们都选择最优的 和 来最小化 (因为 正是当前轮的目标函数),这意味着每轮迭代都会努力使得这个 尽可能小。只要每个弱分类器 的误差率 (即比随机猜测好),那么 就小于1。随着迭代次数 的增加,多个小于1的数相乘,这个连乘积会呈指数级下降,从而保证训练误差的快速收敛。
这个上界的存在性是AdaBoost算法能够有效工作的重要理论保障。它告诉我们,只要弱分类器不是完全随机的,AdaBoost就能将它们提升为一个性能越来越好的强分类器,并且训练误差可以趋于零。
11. AdaBoost的训练误差上界细化
在上一节中,我们已经推导了AdaBoost最终分类器 的训练误差上界:
其中 是最终的强分类器,而 是第 轮的归一化因子。 现在,统计机器学习中的定理8.2将进一步揭示这个 具体是如何由每一轮弱分类器的误差率 决定的。
定理8.2的表述:
其中 。
11.1 定理8.2前两行推导: 与 的关系
这部分的目标是证明 ,然后进一步证明它等于 。
11.1.1 证明
我们回顾第 轮归一化因子 的定义,以及我们在推导 时对它的简化形式:
在求 时,我们把求和项根据样本是否被正确分类分为两部分:
我们知道,正确分类样本的权重之和为 ,错误分类样本的权重之和为 :
我们已经推导出了最优的 值:
现在,我们需要将 和 代入 的表达式。 首先计算 :
接着计算 :
现在将这两个结果代回 的表达式:
对于第一项,我们可以将 写成 :
对于第二项,同理将 写成 :
将两项相加:
这表明,每一轮的归一化因子 的值,完全取决于当前弱分类器的加权错误率 。当 接近0.5时, 接近1(性能最差);当 接近0时, 接近0(性能最好)。
11.1.2 证明
这里我们引入 。 首先,我们把 用 来表示: 从 ,我们可以得到 。
现在,我们计算 :
这是一个平方差公式 的形式:
现在,将这个结果代入 :
将2移入平方根内部(2变成4):
解释:这里 代表了弱分类器性能与随机猜测()的差距。如果 越大(即 越小,弱分类器性能越好),那么 就越小, 也就越小。这符合我们的直觉:性能越好的弱分类器,其对应的归一化因子应该越小,从而在训练误差上界中贡献更小的乘数。
11.2 定理8.2第三行推导:
这是定理8.2中最为关键的一个不等式,它将 的具体形式与指数函数联系起来,为训练误差的指数级下降提供了直接证明。我们来用两种方法证明它。
前提条件:这个不等式成立的前提是 是一个实数,且 。当 时,。如果 ,则 ,此时不等式两边都为1,等号成立。如果 ,则 ,但由于 是平方项,不等式同样成立。在AdaBoost中,我们通常要求 ,否则会丢弃该弱分类器。
11.2.1 方法一:泰勒展开法
泰勒展开是一种将复杂函数近似为多项式的方法,在某个点附近,函数和它的泰勒展开式非常接近。我们可以利用这一点来比较两个函数的大小。
我们需要证明:,然后令 。
步骤1:函数定义和泰勒展开 我们令 和 。 我们将在 处对这两个函数进行泰勒展开。
泰勒展开公式: 对于一个函数 在 处的泰勒展开是: 在 处,它简化为:
对 进行泰勒展开:
所以 的泰勒展开是: 注意:对于 在 上的展开,所有后续项都是负的。这是因为它的高阶导数在 处会交替出现负号。
对 进行泰勒展开:
所以 的泰勒展开是:
步骤2:比较两个泰勒展开式 当 是一个很小的正数时 (例如 ,而 通常很小):
- 第一项都是1,相同。
- 第二项都是 ,相同。
- 第三项: 的是 ,而 的是 。显然,后者更大。
- 从第三项开始,对于小的 , 的展开式中,所有后续项都是负的(或0);而 的展开式中,后续项符号交替,但从 项开始,其绝对值通常会更大。
更严谨地说,我们证明 for 。 考虑函数 . 我们要证明 . . 求导: 当 时,我们知道 且 。 所以 ,因此 for . 因为 且 在 上,所以 在 上是单调递增的,因此 for . 即 。
步骤3:代入 我们已经证明了 。 现在,我们用 代替 。由于 意味着 ,所以 。 此外,由于 ,并且 是误差率,最小为0,最大为0.5(我们只考虑 的情况)。 所以 。 那么 ,因此 。 这满足 的条件。
将 代入不等式 : 这正是我们要证明的定理8.2的第三行!
解释:这个不等式至关重要,因为它表明 可以被一个指数形式的项 所上界。这意味着,如果每次迭代弱分类器 的性能都比随机猜测好一点(即 ),那么 将是一个小于1的正数。当所有这样的项连乘起来时,整个训练误差上界 将会以指数速度下降。
11.3 KL散度与对数性质
直观理解KL散度: KL散度是衡量两个概率分布之间差异的一种度量。在AdaBoost的背景下,我们可以将它与理想分类器和实际分类器的表现联系起来。
假设我们有两个伯努利分布 和 。 KL散度定义为:
Pinsker不等式指出:
这个不等式非常重要,因为它建立了KL散度与两个概率分布之间的L1距离(或者说它们成功概率之差的平方)之间的关系。
如何与AdaBoost联系起来? 在AdaBoost中,我们每一次迭代都在试图训练一个弱分类器 ,使其性能接近于理想情况。 如果我们将真实分类的概率看作 (例如理想分类器对样本分类正确的概率),将弱分类器 的误差率 看作某种“偏离”,那么 可以被视为弱分类器相比随机猜测的优势。
在《统计机器学习》中直接给出的形式是:
重新排列这个不等式:
然后两边取指数:
从信息论角度的简单理解: KL散度通常是非负的,它表示了我们从一个概率分布 切换到另一个概率分布 所需要的信息量。当这个散度较大时,说明两个分布差异大。如果我们将 AdaBoost 每一轮的优化过程看作是调整样本权重,使得数据分布更“偏向”那些难分类的样本,这个过程与减少 KL 散度(或类似概念)是相关的。
12. 为什么定理8.2的第三行如此重要?
在上一节,我们推导了定理8.2,建立了归一化因子 与弱分类器误差率 以及 之间的关系:
现在,我们来深入分析为什么其第三行不等式 如此关键。
12.1 从乘积形式到指数形式的转换
12.1.1 核心作用:将训练误差上界从乘积转换为指数
我们知道,AdaBoost 最终分类器的训练误差上界是所有归一化因子 的连乘积: 如果止步于此,我们得到的是一个乘积形式的上界。要理解这个乘积会如何随着 的增加而变化,特别是它能否快速下降,直观上并不容易。
定理8.2的第三行提供了关键的转换:
通过这个不等式,我们可以将整个乘积形式的上界转化为指数形式:
解释:这个转换是核心!它把一个难以直观判断收敛速度的乘积,变成了一个清晰的负指数函数。指数函数 具有快速下降的特性。只要 随着 的增加而累积,训练误差的上界就会以指数速度下降。
12.1.2 为什么指数形式更“好”?
- 直观清晰的收敛速度:指数下降速度远超多项式下降速度。当 趋于无穷时,如果 能够无限增大(即每个 都略大于零),那么训练误差将以指数速度趋近于零。
- “弱可学习性”的体现:即使每个 都非常小(意味着每个弱分类器只比随机猜测好一点点),只要我们迭代足够多的轮数 ,那么 就能累积到一个足够大的值,从而使得 趋近于零。这完美地体现了“弱学习器可以被提升为强学习器”的理论,即 只需要找到一系列性能略高于随机的基分类器,就可以通过集成方法达到任意低的训练误差 。
- 为泛化误差分析奠定基础:训练误差的指数下降是AdaBoost能够取得良好泛化性能的前提。只有模型在训练集上足够好,我们才有机会期待它在未见数据上也表现良好。未来关于泛化误差上界的推导,也会基于这种指数下降的训练误差上界进行。
12.2 函数图像的比较
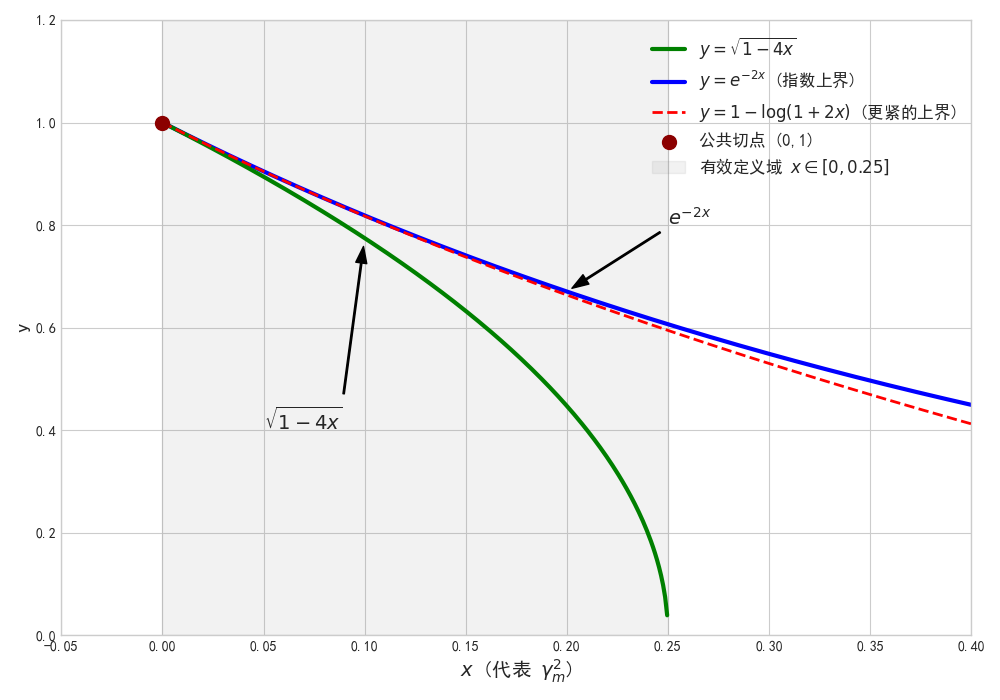
如上图片中,包含了 和 的函数图像(其中 在这里是 )。
- 蓝色的曲线是 。
- 绿色的曲线是 。
在 的区间内(对应于 ),我们可以清晰地看到绿色曲线始终位于蓝色曲线上方(或在 处相切)。
- 当 时, 且 ,两者相等。
- 当 且 时,。
13. 推论8.1:训练误差的指数衰减
13.1 推论的声明与直观意义
推论8.1 (二分类问题 AdaBoost 的训练误差):
如果存在一个常数 ,使得对所有 ,弱分类器 的误差率 满足:
或者等价地,其“优势”参数 满足 ,则最终分类器的训练误差有以下上界:
这个推论告诉我们:
- 稳定的弱学习器性能:如果AdaBoost算法在每轮迭代中都能找到一个“不太差”的弱分类器(即其错误率 始终小于 ,或者说其分类能力至少比随机猜测好一个固定的量 ),
- 训练误差指数级下降:那么随着迭代次数 的增加,最终分类器在训练集上的错误率将以指数级速度趋近于零。
- “弱可学习到强可学习”的直接体现:这个推论是“弱可学习性等价于强可学习性”这一理论在实践中的直接体现。它意味着,即使每个弱分类器只比随机猜测稍微好一点点(比如 ,那么 ),但只要能够持续找到这样的弱分类器,通过足够多的迭代(即增加 ),AdaBoost就能够将训练误差降到任意小。
13.2 推论8.1的详细推导
推论8.1的证明直接利用了定理8.2的最终结果以及前提条件。
推导步骤:
步骤1:引用定理8.2的最终上界 我们从定理8.2的最后一行开始,它给出了AdaBoost训练误差的上界:
步骤2:应用推论的前提条件 推论8.1的前提是存在一个常数 ,使得对于所有的 ,都有 。 这意味着:
因此,它们的平方也满足:
现在,我们将这个不等式代入求和项 :
由于 是一个常数, 也是常数:
所以,我们得到:
步骤3:代回指数函数 我们将这个新的下界代回指数函数的上界表达式中。由于指数函数 是一个单调递减函数(当 越大时, 越小),因此: 如果 ,那么 。 在这里,我们有 ,所以取负号后有 。 因此:
步骤4:得出最终结论 结合所有步骤,我们得到了推论8.1的结论:
这个推导是严谨的。
13.3 推论的重要性
- 理论保证:推论8.1为AdaBoost的训练误差收敛性提供了强有力的理论保证。它表明,只要基分类器能持续地比随机猜测做得好一点,算法就能将训练误差降到任意低。
- 算法鲁棒性:它解释了为什么AdaBoost对弱分类器的选择并不“挑剔”,即使是简单的决策树桩,只要满足弱学习器的条件,AdaBoost也能将其“提升”到很高的精度。
- 迭代次数与性能关系:它直接地将迭代次数 与训练误差的指数衰减联系起来,让我们可以根据所需的精度估算出大致的迭代次数。