线性支持向量机与合页损失 (Hinge Loss)
1. 损失函数在机器学习中的作用
在机器学习中,我们通常通过最小化一个损失函数 (Loss Function) 来训练模型。损失函数衡量模型预测值与真实值之间的“差距”或“误差”。最小化损失函数的目标,是找到一组模型参数,使得模型在训练数据上的表现尽可能好。
例如:
- 线性回归通常使用均方误差 (Mean Squared Error, MSE) 作为损失函数。
- 逻辑回归通常使用对数损失 (Log Loss / Cross-Entropy Loss)。
SVM 也不例外,它也可以被视为最小化一个特定的损失函数。
2. 回顾线性支持向量机的原始问题
从线性支持向量机而来,我们先回顾一下软间隔线性支持向量机的原始优化问题。给定训练数据集 ,其中 。问题形式为:
其中, 是松弛变量, 是惩罚参数。
3. 定义合页损失 (Hinge Loss)
在讨论合页损失之前,我们先定义一个常用的操作符:正部函数 (Positive Part Function)。 解释:这个函数简单地取输入值和 0 之间的较大者。如果输入是正数,就返回它本身;如果输入是负数或零,就返回 0。
现在,我们定义合页损失。对于一个样本 ,其损失定义为: 解释:
- 其中的 正是我们之前定义的函数间隔 。
- 所以合页损失可以写成 .
- 函数图像:
- 当 时(即样本被正确分类且函数间隔大于或等于 1,位于间隔边界上或正确一侧),。此时,合页损失为 。这意味着当样本被“足够正确”地分类时,损失为零。
- 当 时(即样本位于间隔边界和决策超平面之间,或被错误分类),。此时,合页损失为 。损失随着函数间隔的减小而线性增加。
下图能够更清晰地展示合页损失的形状:
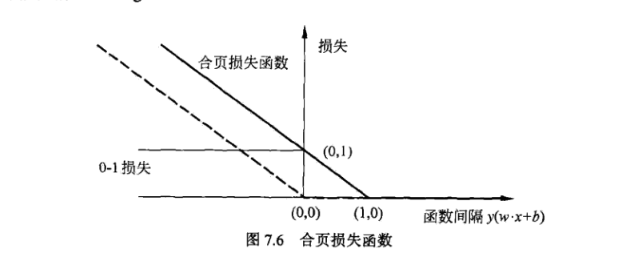
- 当函数间隔 时,损失为 0。
- 当函数间隔 时,损失呈线性增加。
4. 松弛变量 与合页损失的等价性
现在,我们来证明线性 SVM 原始问题中的松弛变量 实际上等价于合页损失。
回顾松弛变量的定义和约束:
我们可以将约束 1 重新整理一下:
现在,考虑原始优化问题的目标函数: 我们要最小化 。在满足 和 这两个条件的前提下,为了使 尽可能小,每个 的取值应该尽可能小。 因此,对于每个 ,它的最优取值将是满足这两个约束的最小值。 这个最小值恰好就是: 解释:
- 如果 (即 ),那么为了最小化 ,我们取 。这符合 。
- 如果 (即 ),那么为了最小化 ,我们取 。这符合 ,且 。
所以,我们可以直接用 来替换原始问题中的 。
5. 将 SVM 原始问题表示为正则化经验风险最小化
将 代入原始优化问题:
这就是线性支持向量机从合页损失角度的理解!
- 正则化项 (Regularization Term):
- 它旨在最小化模型复杂度,防止过拟合。这被称为 L2 正则化。最小化 实际上对应于最大化间隔。
- 经验风险项 (Empirical Risk Term):
- 它衡量模型在训练数据上的分类损失,即模型拟合训练数据的程度。这里的损失函数就是合页损失。
- 参数 平衡了正则化项和经验风险项的重要性。
因此,==线性支持向量机可以被看作是一个在 L2 正则化下,最小化合页损失的优化问题。==
6. 合页损失与 0-1 损失的比较
在分类问题中,理想的损失函数是 0-1 损失 (Zero-One Loss): 或者,用函数间隔表示: 解释:
- 当样本被错误分类时(函数间隔 ),损失为 1。
- 当样本被正确分类时(函数间隔 ),损失为 0。
为什么不直接优化 0-1 损失? 因为 0-1 损失是一个非凸、不连续、不可微的函数。这意味着它有许多局部最小值,并且不能使用梯度下降等基于梯度的优化方法进行求解,是一个 NP-hard 问题。
合页损失作为 0-1 损失的“替代品”:
- 上界:合页损失是 0-1 损失的一个上界。
- 当 时,合页损失为 ,此时 。而 0-1 损失为 1。所以合页损失 0-1 损失。
- 当 且 时,合页损失为 。而 0-1 损失为 0。所以合页损失 0-1 损失。
- 当 时,合页损失为 0。而 0-1 损失也为 0。所以合页损失 0-1 损失。
- 凸性:合页损失是一个凸函数。这使得整个优化问题( 也是凸函数,凸函数之和仍是凸函数)成为一个凸优化问题,可以被高效地求解,并且能保证找到全局最优解。
- 间隔惩罚:合页损失对那些“分类正确但不够自信”的样本(即 的样本)仍然施加惩罚,这符合 SVM 最大化间隔的思想。它促使模型不仅要正确分类,还要让样本尽可能远离决策边界,落在间隔之外。
总结
从合页损失的角度看线性 SVM,它提供了一个更通用的机器学习框架理解:
- SVM 的原始优化问题(带松弛变量和约束)可以等价地转换为一个无约束的正则化经验风险最小化问题。
- 在这个无约束问题中,L2 范数惩罚项 () 用于控制模型复杂度(最大化间隔),而合页损失 () 则作为衡量分类误差的损失函数。
- 合页损失是一个凸函数,它作为理想但难以优化的 0-1 损失的凸替代品,使得 SVM 的优化问题变得可解且高效。同时,合页损失能够惩罚那些在间隔内部的样本,体现了 SVM 追求最大间隔的特性。